
Sprachassistenten sind schon lange ein omnipräsentes Gadget technikverliebter Geeks. Sie unterstützen bei ad-hoc Aufgaben (Tee-Timer stellen, Aussentemperatur ansagen) und integrieren sich hervorragend in Heimautomatisierung und andere Drittanbieter-Systeme. Bedauerlicherweise kommt bei all diesen Spielereien der Datenschutz bedeutend zu kurz. Mithilfe verschiedener Open-Source-Tools lässt sich ein einfacher Sprachassistent ohne Cloud-Zwang nachbauen – was für die meisten Anforderungen durchaus genügen dürfte.
Anforderungen
Offline-Sprachassistenten gibt es in verschiedenen Ausprägungen – generell muss einem jedoch klar sein, dass lokal betriebene Selbstbau-Siris den cloud-basierten Pendants in Puncto Funktionsvielfalt nicht das Wasser reichen können. Der Grund hierfür ist ganz einfach – kommerzielle Produkte greifen auf nahezu unerschöpfliche Rechenkapazität und unzählbare Benutzerdaten zu. Siri, Alexa und co. lernen täglich durch Milliarden Benutzer hinzu – private Assistenten müssen sich mit der Familie als Benutzerstamm zufriedengeben. Auch sind die Rechenkapazitäten eines Einplatinencomputers selbstverständlich verhältnismässig ausserordentlich limitiert. Das Erkennen von vollständigen Sätzen („Hey, schalte das Radio ein“, „Schalte doch bitte das Radio ein“) ist eine komplexe Aufgabe – sinnvoller ist es, kurze Kommandos zu wählen („Radio einschalten“).
Die Frage ist also – was will man mit dem selbstgebauten Sprachassistenten erreichen? Wer E-Mails diktieren, Kalender pflegen lassen oder umfassende Online-Recherchen automatisieren will, wird einem hohen Aufwand gegenüber blicken. Ein Eigenbau lohnt sich vor allem dann, wenn die Anzahl an zu integrierenden Features überschaubar ist und benötigte Funktionen nicht allzu viel Rechenkapazität benötigen. In meinem Fall waren die Use-Cases überschaubar:
- Auslesen von Temperatur-/Feuchtigkeitssensoren pro Zimmer
- Ein-/Ausschalten von Steckdosen
- Abspielen von Internetradio
- Auslesen der Infrastruktur-Überwachung
- Erzählen schlechter Witze
Wichtig war mir vor allem die Integration in Drittanbieter-Applikationen per REST-API ohne aufwändig programmieren zu müssen. Installiert werden sollte das Ganze auf einem Raspberry Pi oder einem vergleichbaren Mini-Rechner, der kostengünstig rund um die Uhr zu betreiben ist.
Open Source-Optionen
Die Auswahl an denkbaren Optionen ist groß – hier ein kleiner Überblick der Tools, die ich mir näher angesehen habe.
Snips.ai
Snips.ai ist bzw. war ein auf Python basierter Assistent, welcher Stimmerkennung und -ausgabe mit sich bringt. Nach der Installation, die ein kostenloses Entwickler-Konto benötigte, konnte die Software komplett offline betrieben werden. Für Rufwörter und hinterlegte Kommandos wurde vorab ein Machine Learning-Muster heruntergeladen. Eigene Logik konnte in Form von Apps entwickelt und sogar mit anderen Entwicklern geteilt werden.
Snips.ai war tatsächlich zuerst mein Favorit, bis SONOS das französische Unternehmen im November 2019 aufkaufte und die Entwicklungswerkzeuge kurzerhand einstellte. Bis dahin aufgesetzte Assistenten ließen sich weiter betreiben, jedoch nicht mehr anpassen – neue Geräte waren fortan außen vor. Danke für nichts, SONOS.
SOPARE
Mit SOPARE (Sound Pattern Recognition) gibt es ein weiteres Python-Projekt, welches offline in Echtzeit auf Mikrofon-Eingaben reagiert. Wörter einfacher Kommandos müssen einzeln eingesprochen und trainiert werden – nach 3 Aufnahmen erreicht das Framework schon eine gute Trefferquote. Das Framework arbeitet rein auf der Kommandozeile, eine Web-Oberfläche gibt es nicht – Integrationen in andere Systeme müssen programmatisch erfolgen. Eine Wake Word-Funktionalität konnte ich der Dokumentation nicht entnehmen – folglich scheint die Applikation permanent mit zu lauschen. Bedauerlicherweise scheint die Entwicklung des Frameworks stehen geblieben zu sein – der letzte Commit im Git-Repository ist 2 Jahre alt.
Rhasspy
Rhasspy ist ein ebenfalls auf Python aufbauendes Sprachassistenten-Framework, welches sich in eine Vielzahl existierender Dienste zur Spracherkennung und -synthese sowie Kommandosteuerung integriert und dabei viele Sprachen unterstützt. Es ist auch mit den beliebten Tools Home Assistant und Node-RED kompatibel.
Zentraler Kontrollpunkt ist eine Web-Oberfläche, in der die benutzten Frameworks, die einzelnen Sentences (erkennbare Satzfragmente) und Intents (Kommandos) definiert werden. Auch kann der Assistent direkt über die Oberfläche aktiviert und getestet werden.
In der Installationsdokumentation gibt es Framework-Empfehlungen je nach Sprache – ich habe mich für die folgenden entschieden:
- Wake Word (Rufwort): porcupine
- Speech2Text (Spracherkennung): pocketsphinx
- Text2Speech (Sprachausgabe): pico-tts
Vorsicht: Einige der in der Dokumentation aufgelisteten Alternativen sind wieder cloud-basiert (z.B. Google WaveNet) oder benötigten personalisierte Accounts, womit wir wieder beim Thema Datenschutz wären.
Rhasspy ist nicht in der Lage selbstständig erkannte Kommandos (z.B. Aussentemperatur ausgeben) anzusteuern und benötigt hierfür Home Assistant, Node-RED oder einen MQTT-Broker für andere Systeme.
Home Assistant
Home Assistant ist ein Framework für Heimautomatisierung mit mehr als 1500 Integrationen. Es zielt vor allem auf die Steuerung verschiedener Hausgeräte, wie beispielsweise Thermostate, Steckdosenleiste, Smart Speaker, etc. ab. Durch das Auslesen von Router-, WLAN- und Bluetooth-Schnittstellen kann es die Anwesenheit einzelner Benutzer erkennen und verbundene Geräte gemäß Vorlieben steuern (z.B. Musik anschalten, Heizung aktivieren, etc.). Für den Raspberry Pi gibt es ein eigens angepasstes Mini-Betriebssystem (hass.io), die die Platine kurzerhand zur Schaltzentrale des Hauses macht.
Ich hatte mir Home Assistant deswegen angeschaut, weil sich Rhasspy damit verknüpfen lässt. Leider bootete das System jedoch nicht auf meinem Raspberry Pi und ich bin auch skeptisch, ob ich den für das Mikrofon-Array benötigten Soundtreiber hätte übersetzen können. In allem bietet Home Assistent viel mehr als das, was ich benötige – deswegen habe ich es nicht näher in Betracht gezogen.
Node-RED
Node-RED ist Werkzeug für die grafische Entwicklung von vernetzten Systemen, beispielsweise für IoT-Projekte. So werden Programmabläufe (flow) direkt im Web-Browser entworfen und Systeme mit Standard-Protokollen per Baustein (node) vernetzt. Das Framework unterstützt eine breite Fülle an gängigen Protokollen, unter anderem tcp/udp, MQTT, http/https und WebSocket. Auf der Webseite des Projekts gibt es einen Katalog mit Erweiterungsmodulen sowie vordefinierten Flows. Programmabläufe können in JSON exportiert und mit anderen geteilt werden.
Das ursprünglich von IBM gegründete Projekt wird in node.js entwickelt. Die einzelnen Nodes eines Flows können mit JavaScript programmiert werden.
Hardware- und Software-Aufbau
Ich habe mich schlussendlich für die Kombination von Rhasspy und Node-RED entschieden, da sich so die meisten Funktionen und Integrationen ergeben. Rhasspy vereint alle für einen Offline-Sprachassistenten essenzielle Komponenten; mithilfe von Node-RED lassen sich spielerisch und mit wenig Code umfassende Integrationen (Temperatur-Sensor, Online-Radio,…) entwickeln.
Zusammengefasst besteht mein Setup aus den folgenden Komponenten:
- Raspberry Pi 3
- ReSpeaker 4 Mic Array for Pi (4-Kanal-Mikrofon und LED-Laufleiste für Animationen)
- Raspbian Buster Lite
- Docker Community Edition
- Rhasspy Server-Image
- Raspberry Pi 4
- Raspbian Buster Lite
- Docker Community Edition
- Eclipse Mosquitto Image (MQTT)
- Node-RED Image
- weitere Anwendungen, die mit Node-RED verknüpft werden
- Online Radio-Container
- Joke-API
- Verschiedene Mikrocontroller
- ESP32 + Bosch BME280 für Temperaturüberwachung
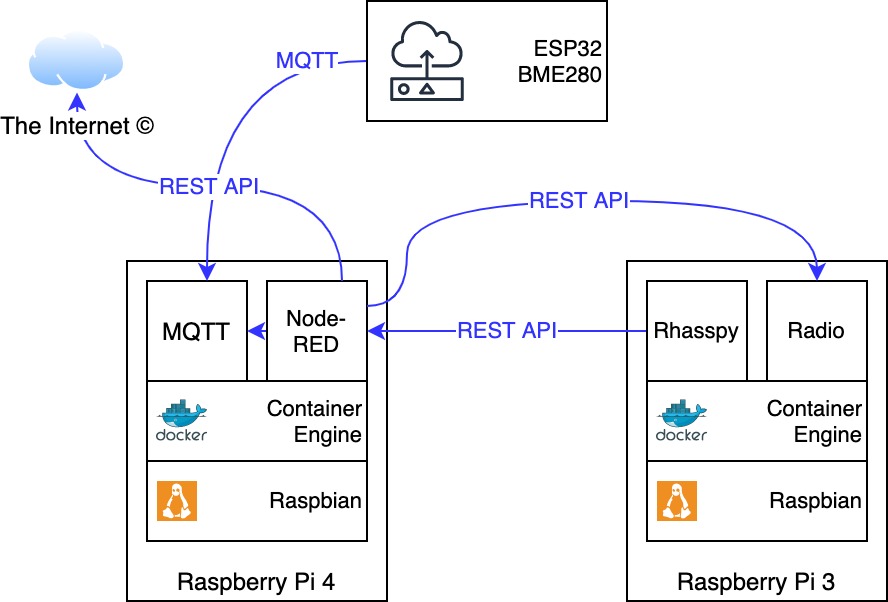
Selbstverständlich kann man alle Container auch zusammen auf einem Raspberry Pi betreiben – ab dem Pi 3 stehen genügend Ressourcen zur Verfügung, die Zero-Platinen sind jedoch weniger empfehlenswert. In meinem Fall war der Pi 4 schon belegt und in einem Schrank verbaut und den Pi 3 hatte ich noch über.
Rhasspy lässt sich natürlich auch nativ auf Debian bzw. Raspbian in einem Virtualenv installieren – jedoch sind sowohl die Installation als auch das Aktualisieren auf neuere Versionen wenig komfortabel. Container-Images sind hier bedeutend einfacher zu handhaben. Die beiden Projekte liefern in regelmäßigen Abständen neue Images aus und so genügt ein Downloaden und Neustarten des Containers, um die Anwendungen zu aktualisieren.
Installation
Auf die Installation von Raspbian und Docker CE gehe ich an dieser Stelle nicht ein – hierzu gibt es genügend Dokumentationsquellen im Internet:
Für das verwendete Mikrofon gibt es auf GitHub einen Treiber, dieser muss noch übersetzt werden:
# git clone https://github.com/respeaker/seeed-voicecard.git
# cd seeed-voicecard
# ./install.shDieser Vorgang dauert ca. 20 Minuten, dabei wird eine spezifische Kernel-Version installiert und die entsprechenden Module übersetzt. Anschließend sollte man davon absehen, die Pakete raspberrypi-kernel und raspberrypi-kernel-headers zu aktualisieren – idealerweise sperrt man diese:
# apt-mark hold raspberrypi-kernel{,-headers}Ich habe mich dazu entschieden, die beiden Container via docker-compose aufzusetzen. Daher werden noch die entsprechenden Python-Module benötigt:
# pip install docker docker-composeDie entsprechenden Konfigurationsdateien sehen wie folgt aus:
/home/pi/node-red/docker-compose.yml
version: "3"
services:
node-red:
container_name: nodered
image: nodered/node-red:latest
ports:
- "1880:1880/tcp"
environment:
TZ: 'Europe/Berlin'
volumes:
- node-red-data
restart: unless-stoppedNeben dem Image werden hier auch die Zeitzone und eine Weiterleitung des TCP-Ports 1880 definiert. Über diesen Port ist anschließend die Web-Oberfläche erreichbar.
/home/pi/rhasspy/docker-compose.yml
version: "3"
services:
rhasspy:
container_name: rhasspy
image: "synesthesiam/rhasspy-server:latest"
ports:
- "12101:12101"
volumes:
- "./profiles:/profiles"
devices:
- "/dev/snd:/dev/snd"
command: --user-profiles /profiles --profile de
restart: unless-stopped
Auch hier wird wieder ein TCP-Port für eine Web-Oberfläche definiert: 12101. Darüber hinaus wird für die Anwendungskonfiguration ein Volume erstellt. Mit dem Parameter --profile de wird Rhasspy für die deutsche Sprache konfiguriert.
Anschließend können die beiden Container erstellt und gestartet werden:
# cd /home/pi/node-red
# docker-compose up -d
# cd /home/pi/rhasspy
# docker-compose up -dEventuell fehlende Netzwerke müssen noch erstellt werden:
# docker network create node-red_default
# docker network create rhasspy_defaultDer erste Start
Anschließend sollte die Node-RED Web-Oberfläche (http://ip-adresse:1880) eine leere Übersicht anzeigen:
Die Web-Oberfläche lässt sich mit einem Passwort versehen bzw. deaktivieren – entsprechende Hinweise hierzu finden sich in der offiziellen Dokumentation.
Nach dem ersten Aufruf der Rhasspy-Oberfläche (http://ip-addresse:12101) erscheint ein Hinweis über benötigte Dateien, die heruntergeladen werden müssen:
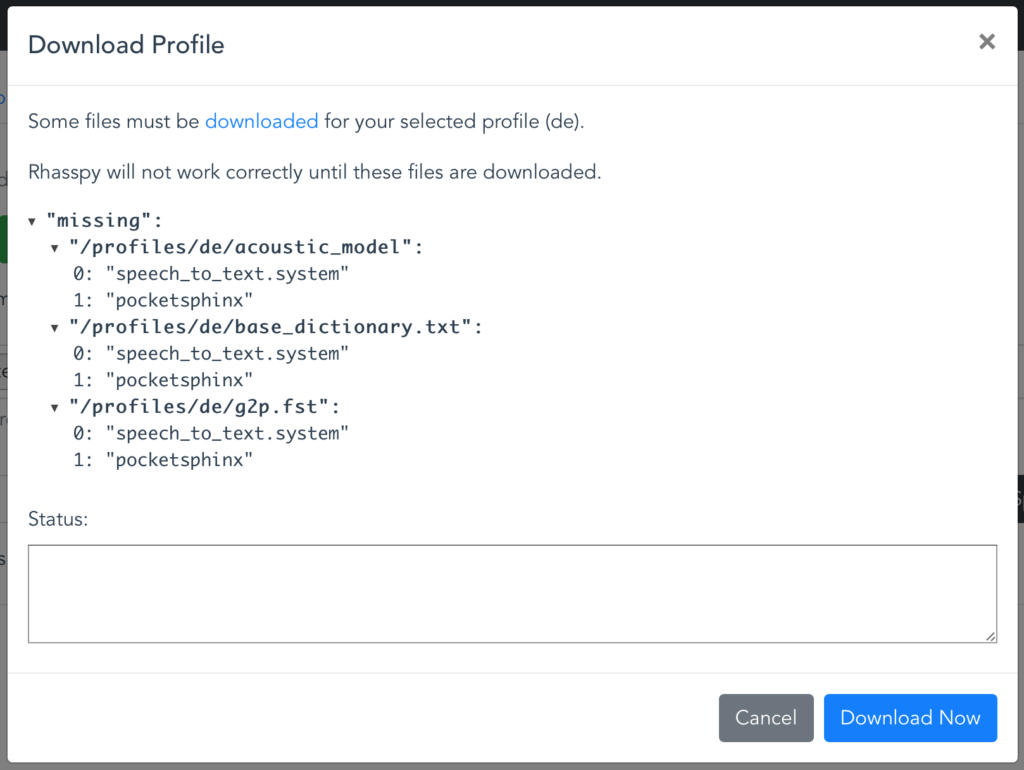
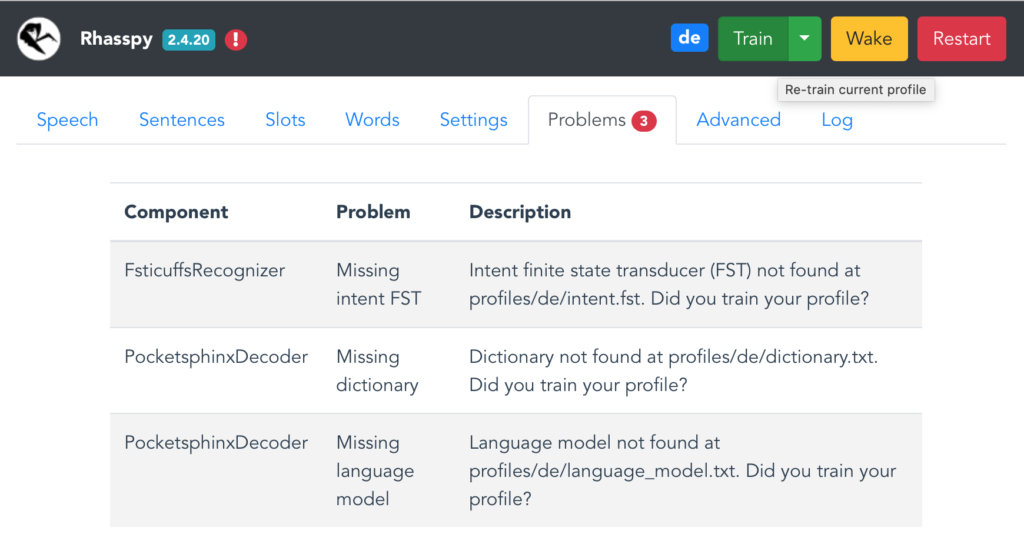
Hierbei handelt es sich hauptsächlich um sprachspezifische Profile und Wörterbücher. Nach einem Klick auf Problems sind noch weitere fehlende Dateien zu sehen – weil der Assistent noch nicht trainiert wurde. Mit einem Klick auf Train wird das behoben.
Ausblick
Im ersten Teil der Artikelserie haben wir uns einen groben Überblick über die Software-Vielfalt verschafft und zwei grundlegende Komponenten für einen Sprachassistenten installiert: Node-RED und Rhasspy. Der nächste Teil dreht sich ganz um den weiteren Aufbau des Konstrukts und die Verknüpfung der benötigten Komponenten.



{kind=link}