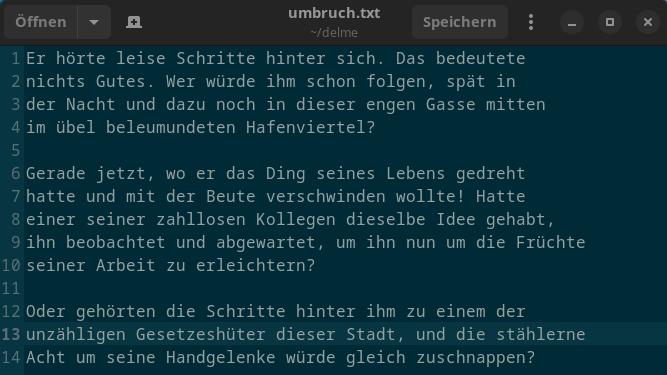
Folgender Anwendungsfall: Ihr habt einen Text von einer Webseite, aus einer E-Mail oder von irgendwoher. Dieser Text beinhaltet harte Umbrüche und Absätze. Ziel ist es, diesen in einen Fliesstext umzuwandeln, ohne die Absätze zu verlieren. Im Titelbild seht ihr einen Beispieltext.
Einer ähnlichen Aufgabe hatte sich Lioh bereits in diesem Artikel im Februar angenommen. Allerdings ging es dort darum, überflüssige Leerzeilen zu entfernen. Mein Anwendungsfall kommt bei mir häufig vor, z. B. wenn bei Artikeleinsendungen die harten Umbrüche entfernt werden müssen. Auf den ersten Blick sieht die Aufgabe einfach aus: Man entfernt mit "Suchen und Ersetzen" in einem Texteditor die Zeilenumbrüche. Tatsächlich gibt es einige Hürden zu überwinden.
Das erste Problem sind die Zeilenumbrüche. Leider gibt es drei verschiedene Arten: \r\n, \r, oder \n. Ausserdem würde das Ersetzen der Zeilenumbrüche die Absätze zerstören, da diese ebenfalls durch einen Zeilenumbruch abgebildet werden. Somit müssen leere Zeilen erkannt und dürfen nicht entfernt werden. Zudem müssen Whitespace-Zeichen berücksichtigt werden, die sich vor oder hinter einem Zeilenumbruch befinden können. Hier ist ein Bild des gewünschten Ergebnisses:
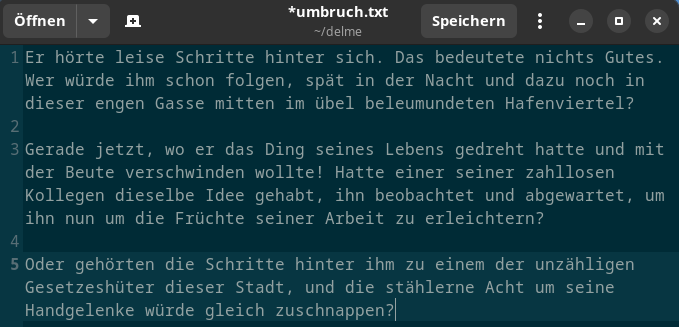
Wie man sieht, wurden die Umbrüche entfernt (Fliesstext) und die Absätze beibehalten. Um das zu erreichen, habe ich einen regulären Ausdruck im Suchen/Ersetzen-Dialog des Texteditors Gedit verwendet. Im Suchen-Feld befindet sich der reguläre Ausdruck und im Ersetzen-Feld ein Leerzeichen. Ausserdem muss unten die Option 'Regulärer Ausdruck' eingeschaltet werden.
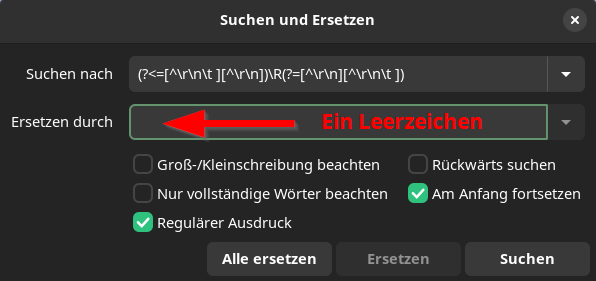
Hier, zum Kopieren:
(?<=[^\r\n\t ][^\r\n])\R(?=[^\r\n][^\r\n\t ])
Was macht dieses REGEX-Ungetüm? Man kann es in drei Teile aufteilen:
- (?<=[^\r\n\t ][^\r\n]): Dies ist ein sogenannter positiver Lookbehind-Ausdruck (?<=), der eine Bedingung darstellt, die vor dem übereinstimmenden Text erfüllt sein muss. In diesem Fall bedeutet die Bedingung [^\r\n\t ][^\r\n], dass vor der aktuellen Position zwei Zeichen stehen:
- Das erste Zeichen darf keines der folgenden sein: Zeilenumbruch (\r), Newline (\n) oder Tab (\t).
- Das zweite Zeichen darf keines der folgenden sein: Zeilenumbruch (\r) oder Newline (\n). - \R: Dieser Teil des Ausdrucks sucht nach einem Zeilenumbruchzeichen. \R repräsentiert einen Zeilenumbruch in einem regulären Ausdruck und kann verschiedene Arten von Zeilenumbrüchen abdecken, z.B. das Windows-Zeilenumbruchformat (\r\n), das Unix-Zeilenumbruchformat (\n) und das Mac-Zeilenumbruchformat (\r)
- (?=[^\r\n][^\r\n\t ]): Dies ist ein positiver Lookahead-Ausdruck (?=), der eine Bedingung darstellt, die nach dem übereinstimmenden Text erfüllt sein muss. Die Bedingung [^\r\n][^\r\n\t ] stellt sicher, dass nach dem Zeilenumbruchzeichen zwei Zeichen folgen:
- Das erste Zeichen darf keines der folgenden sein: Zeilenumbruch (\r) oder Newline (\n).
- Das zweite Zeichen darf keines der folgenden sein: Zeilenumbruch (\r), Newline (\n) oder Tab (\t).
Zusammengefasst sucht dieser reguläre Ausdruck nach einem Zeilenumbruchzeichen, das von Zeichen umgeben ist, die keine Zeilenumbrüche oder Tabulatorzeichen sind. Es erkennt praktisch einen Zeilenumbruch, der von regulärem Text umgeben ist und nicht am Anfang oder Ende einer Zeile steht.
Was mir nicht gelungen ist, ist den regulären Ausdruck im Terminal auszuführen. Ich habe es hiermit versucht, was nicht funktioniert:
sed -r '(?<=[^\r\n\t ][^\r\n])\R(?=[^\r\n][^\r\n\t ])' umbruch.txtFalls ihr eine Idee habt, wie das im Terminal funktioniert, dann schreibt es gerne in die Kommentare.



Folgender Befehl scheint zu funktionieren, wobei ich hier vereinfacht nur gucke, dass vor und hinter dem Umbruch kein anderer Umbruch steht (im obigen Beispiel werden auch Tabs oder Leerzeichen getestet):
Mittels der sed-Option
-zkann die ganze Datei eingelesen werden indem Zeilen durch das NUL-Zeichen ersetzt werden. sed kann keinen Lookahead or Lookbehind, aber es kennt Gruppen (\(…\)) und Referenzen (\1, etc.) darauf. Hier ist die erste Gruppe das Zeichen vor dem Umbruch, die zweite Gruppe das Umbruchzeichen selbst, welches im Falle von DOS-Endungen\r\nist, sonst wird für einzelne\roder\ngesucht. Die dritte Gruppe ist das Zeichen nach dem Umbruch. Bei einem positiven Fund wird das ganze Konstrukt aus den drei Gruppen durch die erste Gruppe + Leerzeichen + die dritte Gruppe ersetzt. sed's Ersetzung wird mittels's/fund/ersatz/g'auf alle Funde angewendet.Sehr praktisch, vielen Dank, Ralph! Funktioniert auch in Kate (Standard-Texteditor von KDE Plasma) einwandfrei, wie es scheint.
Im Sinne der allüberall notwerndigen Emacs-Propaganda, die hier noch fehlt, wenn man eh schon alle guten Programme auf seinem Linux installiert hat:
emacs --batch test.txt \ --eval "(let ((fill-column (point-max))) (fill-individual-paragraphs (point-min) (point-max)))" \ -f save-buffer
Öffnet die Datei test.txt in einem Buffer, und wendet dann auf den Inhalt die fill-individual-paragraphs Prozedur so an, dass sie effektiv "unfilling" betreibt. ("Fill" hier im Sinne von: nur bis zu Zeichen/Spalte X eine Zeile wachsen lassen, dann hard line breaks einfügen; also das, was die Ausgangsdatei leider hat) Das Ergebnis vom veränderten Text-Buffer wird direkt gespeichert (-f save-buffer).
Der alte Inhalt landet in test.txt~ als Backup.
Referenz zum "Batch Mode": https://www.emacswiki.org/emacs/BatchMode