
Bei unserem Februar-Gewinnspiel ging es darum, aus einer Liste von Telefonaten (Startzeit, Dauer) die maximale Anzahl paralleler Anrufe herauszufinden. Insgesamt haben 23 Teilnehmende einen Lösungsvorschlag eingereicht, wobei 19 davon ein korrektes Ergebnis lieferten. Von diesen Programmen waren 17 in Python und 2 in Shell-Skript geschrieben. Zwei Python und 2 Rust-Programme lieferten falsche Ergebnisse.
Bevor ich in die Details eintauche, möchte ich mich bei allen Teilnehmenden ganz herzlich bedanken. Die eingereichten Beiträge waren sehr spannend und grösstenteils mit viel Liebe und grossem Aufwand gemacht. Insbesondere erinnerten manche Dokumentationen fast an Diplomarbeiten. Die einhellige Meinung der Beitragenden war, dass sie viel Spass an diesem Gewinnspiel hatten, und sich die Zeit an einem verregnetem Wochenende vertreiben konnten. Manche habe die Gelegenheit genutzt, um ihre Programmierkenntnisse aufzufrischen oder zu verbessern.
"Die Aufgabe war eine schöne Beschäftigung für einen Freitag-Nachmittag. Ich mache zwar erst zum zweiten Mal mit, freue mich aber schon auf die folgenden Aufgaben", schreibt Jens.
"Es hat mir viel Spaß gemacht daran teilzunehmen. Ich habe die Chance genutzt, eine für mich neue Programmiersprache (Python) etwas anzuschauen und kennenzulernen. Ich kann mir gut vorstellen, dass es nicht das letzte Python Projekt bleiben wird", meint Theophil.
Lösungsansätze
Ich habe mir selbstverständlich alle Vorschläge angesehen, jedoch nicht jeden davon wirklich verstanden. Deshalb möchte ich hier nur die zwei Hauptansätze erwähnen. Die Daten können aus zwei Perspektiven betrachtet werden, nämlich über die Ereignisse (Anrufe) und über die Zeitachse (Sekunden).
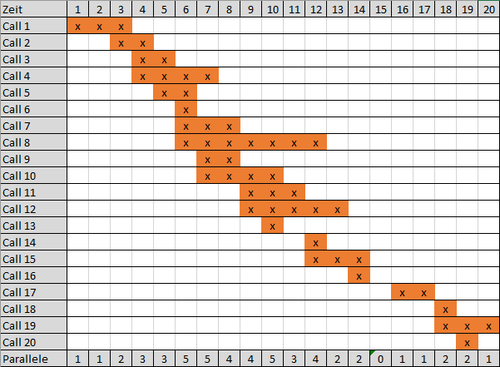
Die meisten Vorschläge orientieren sich an den Anrufen und versuchen eine Schnittmenge der Parallelen zu ermitteln. Dieser Ansatz kommt einem vermutlich als Erstes in den Sinn; er ist aber nicht trivial und enthält einige Fallstricke, die man nicht auf den ersten Blick sieht. Die Schnittmenge muss nicht nur über einzelne Werte, sondern über Tupel (Start, Ende) gebildet werden. Dennoch haben die meisten Einsendungen diese Perspektive verfolgt.
Die zweite Methode orientiert sich an den Zeiteinheiten (Sekunden) und fragt danach, wie viele parallele Anrufe gab es zu einer bestimmten Zeiteinheit. Programmiertechnisch ist dieser Ansatz einfacher umzusetzen, was ich auch an der signifikant kleineren Code-Menge gesehen habe. Die Teilnehmer haben sich ca. 50:50 für die eine oder andere Methode entschieden.
Das richtige Ergebnis
Das korrekte Ergebnis, also die maximale Anzahl paralleler Anrufe beträgt 7 oder 8. Dies hängt davon ab, ob man zwei Anrufe, von denen ersterer in Sekunde x endet und der zweite in Sekunde x beginnt, als parallel oder nicht interpretiert. Diesen Fall gibt es im Datenset genau einmal. Da die Auflösung der Daten bei 1 Sekunde liegt, kann man das nicht genau beantworten; beide Lösungen sind richtig. Würde man in den Bereich von Millisekunden gehen, könnte man entscheiden, ob sich die beiden Anrufe überlappen oder nicht.
Die Dokumentation
Obwohl es nicht zwingender Bestandteil der Aufgabe war, haben fast alle Teilnehmenden ihre Lösungen gut dokumentiert. Dabei stachen einige Erläuterungen äusserst positiv hervor. Weil dort soviel Aufwand hineingesteckt wurde, möchte ich zwei davon hier verlinken:
Die Musterlösung
Anstatt hier alle 19 korrekten Lösungen zu präsentieren, habe ich mich dafür entschieden, eine Musterlösung zu zeigen. Diese ist sozusagen als Essenz aller eingesandten Beiträge über die Zeit entstanden. Hier ist der Code:
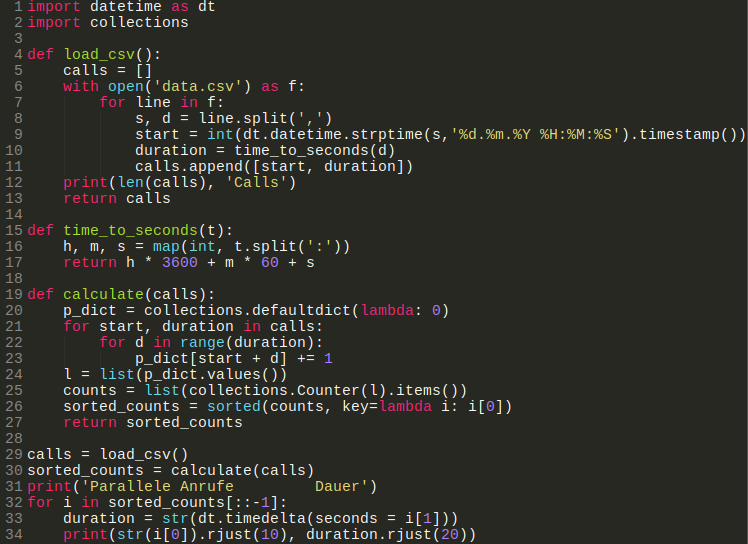
Das ist ein Screenshot, weil ich die Zeilennummern für die Erklärung benötige und Markdown keine Code-Blocks mit Nummern unterstützt. Hier ist der Link zum Code.
Zeilen 1, 2
Die Library datetime wird für die Konvertierung der Datum- und Zeit-Strings benötigt. Die Library collections braucht man, um ein Dictionary mit default-Werten zu initialisieren.
Zeilen 4 bis 13
Die Daten werden von 'data.csv' in die Liste calls eingelesen. Dabei wird der Text des Startzeitpunkts in einen Timestamp, und die Dauer in einen Sekunden-Integer umgewandelt (siehe Zeilen 15 bis 17).
Zeilen 19 bis 27
Hier spielt die eigentliche Musik. Alle Keys des Dictionaries 'p_dict' werden mit 0 initialisiert, damit bei einem Zugriff auf einen unbekannten Key, kein 'KeyError' auftritt, was eine zusätzliche Fehlerbehandlung (except KeyError:) erzwingen würde.
Nun wird über alle Anrufe iteriert. In einer Unterschleife wird über alle Sekunden eines konkreten Anfrufs iteriert. In Zeile 23 kommt der Teil, der den Algorithmus im Kern ausmacht:
p_dict[start + d] += 1Was passiert hier? Jede Sekunde eines andauernden Anrufs wird als Key des Dictionaries verwendet. Für jeden Key wird der Wert des Dictionaries um 1 addiert. Da wir über alle Anrufe iterieren, wird im Dictionary pro Sekunde die Anzahl paralleler Anrufe hinzugezählt.
Beispiel:
-
Sekunde 1 = 1 Anruf
-
Sekunde 2 = 5 Anrufe
-
Sekunde 3 = 3 Anrufe
-
usw.
Dabei werden natürlich nur die Sekunden berücksichtigt, in denen tatsächlich ein Anruf stattgefunden hat. Würde man über die Sekunden des gesamten Monats iterieren, würde das Programm viel zu lange laufen.
In Zeile 24 wird eine Liste der Werte aus dem Dictionary erstellt. Zeile 25 zählt die Häufigkeiten der Werte und erstellt daraus eine Liste. Zeile 26 sortiert die Liste nach den Häufigkeiten.
Zeilen 31 bis 34
Jetzt wird die Liste in umgekehrter Reihenfolge ausgegeben. Die Ausgabe sieht so aus:
Parallele Anrufe Dauer
7 0:01:20
6 0:07:02
5 0:28:49
4 1:16:49
3 4:18:25
2 19:48:39
1 2 days, 18:17:41Die Anzahl paralleler Anrufe wird zusammen mit der Dauer ausgegeben (wie lange waren die parallelen Anrufe aktiv). In Zeile 33 werden die Sekunden in einen Time-String konvertiert. Zeile 34 kümmert sich um die formatierte Ausgabe.
Lesebeispiel: "Während eines Zeitraums von 1 Minute und 20 Sekunden waren 7 Leitungen parallel belegt."
Wie man sieht, lässt sich die Aufgabe mit gut 30 Zeilen Python-Code lösen.
Die Ausführungsgeschwindigkeiten der eingereichten Lösungen waren sehr unterschiedlich. Die langsamste Variante benötigte 28 Minuten, während die schnellste Lösung (wie oben beschrieben) nur 0.2 Sekunden brauchte.
Die Kandidaten und die Verlosung
Diese Teilnehmenden haben eine richtige Lösung eingereicht und nehmen an der Verlosung heute Abend teil:
1 - Max
2 - Tim
3 - Alexander S.
4 - Jens
5 - Hanser
6 - Simon
7 - Leo
8 - Onli
9 - Josslyn
10 - Marcel
11 - Leonid
12 - Jan
13 - Philipp
14 - Jan-Luca
15 - David
16 - Tobias
17 - Alexander M.
18 - Fabian
19 - TheophilIn der Beschreibung des Gewinnspiels wollten wir die eleganteste Lösung prämieren und mit einer Pinetime belohnen. Da so viele Beiträge eingegangen sind, haben wir uns eines Besseren besonnen. Wir fänden es unfair nur eine Person aufgrund ihrer Leistungen auf subjektiver Basis auszuwählen. Deshalb möchten wir die Gewinner:in des Preises unter den 19 korrekten Lösungen auslosen.

Heute Abend, um 19 Uhr ist es so weit. In unserem Matrix-Raum würfeln wir die Gewinner:in des Februar-Gewinnspiels aus. Herzlichen Dank an alle Teilnehmer:innen. Auch wenn ihr nicht gewinnt; dabei sein ist alles. Nach dem Gewinnspiel ist vor dem Gewinnspiel.


