
Manchmal bin ich wirklich begeistert. So auch gestern Abend, als die Nachricht über eine freie Speech-to-Text Engine durch meine Timeline flog. Wir kennen die Firma OpenAI als führend bei praktischen Anwendungen im Bereich der Spracherkennung und der "künstlichen Kunst". Vielleicht habt ihr schon einmal DALL·E ausprobiert, um eure Gedanken in Gemälde umzuwandeln. Viel bekannter ist die Firma aus San Francisco für ihr Sprachmodell GPT-3.
Alle bisherigen Produkte von OpenAI waren kommerzielle Dienste, die sehr beeindruckten, jedoch nicht für jede:n zur Verfügung standen und ausserdem ein grosses Fachwissen erforderten, um im Alltag eingesetzt zu werden. Gestern Abend hat sich das geändert. Die Firma hat ihr neues Sprachmodell Whisper unter der MIT-Lizenz veröffentlicht. Und ich habe es sogleich ausprobiert.
Was macht das Ding? Es ist ein neuronales Netzwerk (nenne es nicht KI), welches Sprache (in Form einer Audio-Datei) in geschriebenen Text übersetzt. Wozu braucht man das? Zum Beispiel um Sitzungen in geschriebene Protokolle umzuwandeln, oder um Podcasts zu transkribieren.
Whisper bietet fünf verschiedene Grössen bei den Sprachmodellen:
- Winzig (tiny): 39 MB
- Basis (base): 74 MB
- Klein (small): 244 MB
- Normal (medium): 769 MB
- Gross (large): 1550 MB
Bis auf das grosse Modell (nur Englisch) gibt es die vier kleineren jeweils in einer englischen und einer mehrsprachigen Version.
Bislang gab es einige Cloud-Dienste, denen man diese Aufgabe für Geld oder Daten lieber nicht anvertrauen wollte. Die gute Botschaft ist, dass Whisper a) freie Software ist, b) sehr einfach zu verwenden ist, und c) überzeugende Ergebnisse liefert. Wer sich für die Details des Systems interessiert, kann diese unter der Quelle oder bei Heise nachlesen. Mich interessiert, ob es funktioniert.
Das Experiment
Man konnte sich bislang aus den Services, Modellen und Anleitungen mit PyTorch, HuggingFace Transformers und viel Fachwissen eine STT-Engine basteln. Das war aber für die halbwegs interessierte Anwenderin kaum machbar. Nun hat sich das Blatt gewendet, und das ist gut so.
Zunächst könnt ihr prüfen, ob ffmpeg auf eurem System installiert ist, was normalerweise der Fall ist. Tippt einfach im Terminal ffmpeg ein, dann seht ihr es, bzw. erhaltet eine Installationsaufforderung, falls es fehlt.
Dann erstellt ihr ein Unterverzeichnis mit beliebigen Namen, z. B. whisper. Nun navigiert ihr im Terminal in dieses Verzeichnis: cd whisper und führt diesen Befehl aus:
pip install git+https://github.com/openai/whisper.git Falls ihr den Python-Installer pip nicht habt, könnt ihr diesen aus dem Software-Store eurer Distribution installieren. Das war es auch schon; mehr muss nicht installiert werden. Was ihr jetzt braucht, ist eine englischsprachige Audio-Datei. Für mein Experiment habe ich knapp 1 Minute aus der letzten Folge des LateNightLinux-Podcasts extrahiert. Hier ist die Datei, die ihr euch anhören solltet, um einen Vergleich zur Transkription zu haben:
Im nächsten Schritt wird diese Audio-Datei in einen Text umgewandelt. Dazu ladet ihr die Audio-Datei (oder eine beliebige andere englischsprachige Datei) unter dem Namen latenightlinux.mp3 in das zuvor erstellte Verzeichnis herunter und verwendet diesen einfachen Befehl:
whisper latenightlinux.mp3 --model medium Das Kommando ist selbsterklärend: Whisper wird auf die Datei latenightlinux.mp3 angewendet, wobei das mittlere Sprachmodell (769 MB) zum Einsatz kommt. Jetzt müsst ihr Geduld haben. In Abhängigkeit von der Leistungsstärke eures Rechners, dauert es etwa 15 Minuten, bis die Transkription erstellt wird. Ihr könnt das im Terminal verfolgen:
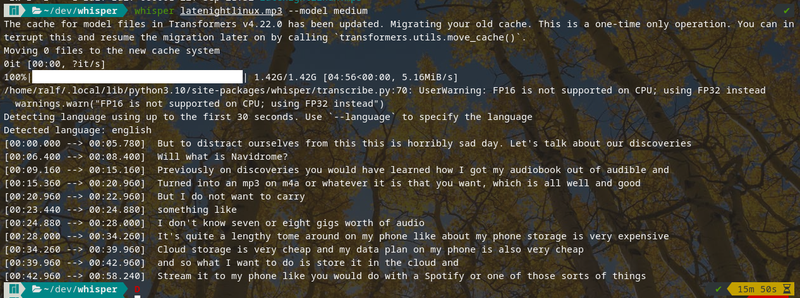
Während Whisper seinen Dienst tut, könnt ihr im Terminal die Transkription in 30 Sekunden Schritten verfolgen. Zum Schluss gibt es im Verzeichnis auch die Text-Datei: latenightlinux.mp3.txt
But to distract ourselves from this, this is horribly sad day. Let's talk about our discoveries. Will, what is Navidrome? Previously on discoveries you would have learned how I got my audiobook out of audible and turned into an mp3 on m4a or whatever it is that you want, which is all well and good but I do not want to carry something like. I don't know seven or eight gigs worth of audio. It's quite a lengthy tome around on my phone like about my phone storage is very expensive. Cloud storage is very cheap and my data plan on my phone is also very cheap and so what I want to do is store it in the cloud and stream it to my phone like you would do with a Spotify or one of those sorts of things.
Nun könnt ihr eure Kopfhörer aufsetzten und die Audio-Datei mit dem transkribierten Text vergleichen. Ich glaube, ihr kommt zum gleichen Ergebnis wie ich: Es ist sehr gut. Jetzt macht euch Gedanken, wie ihr Whisper für eure Zwecke verwenden könnt.
Quelle: https://openai.com/blog/whisper/



Da gibt es noch so ein Tool vom PrototypeFund gesponsertes Audapolis basierend auf der offline Spracherkennung VOSK. Oder als Diktierhielfe mit nerd-dictation.
Anwendung für meine Zwecke: Schüler*innen könnten mit diesem Tool ihre Aussprache trainieren, indem sie (oder ich als Lehrperson) in Worten sehen können, wie ihre gesprochenen/vorgelesenen Fremdsprachen-Texte tatsächlich "verstanden" werden. Wäre echt cool.
Welche Sprachmodelle unterstützt denn large? Und kann man das einfach mit "--model large" ausführen?
Auf Github wird darauf nochmal sehr deutlich eingegangen habe ich gesehen. https://github.com/openai/whisper
Deutsch performed gar nicht so schlecht. Leider benötigt man aber ~10GB VRAM für large.
Awesome! Just look at the transcript above.
wie cool! Danke für die sehr anschauliche Erklärung!