Im Laufe der Jahre haben sich bei mir unzählige (PDF-)Dokumente zum Themenbereich Lehramt und Schule angesammelt. Längst lohnt sich der Zeitaufwand nicht mehr, da noch mit Schlagworten oder systematischen Einordnungen zu hantieren - nur gelegentlich benötige heute noch ich einzelne Stellen aus dem Wust von Materialien.
In solchen Fällen ist es gut, wenn man einfach ein Suchtool auf den Bestand ansetzen kann und sich ein bisschen durch die Resultate klickt. Eine Reihe von Tools erledigen diesen Job, indem sie z. B. vorab einen Index der Inhalte bilden. Clapgrep kommt ohne einen solchen Index aus - und ist trotzdem sehr, sehr flott unterwegs.
 Ansicht der Suchresultate
Ansicht der Suchresultate
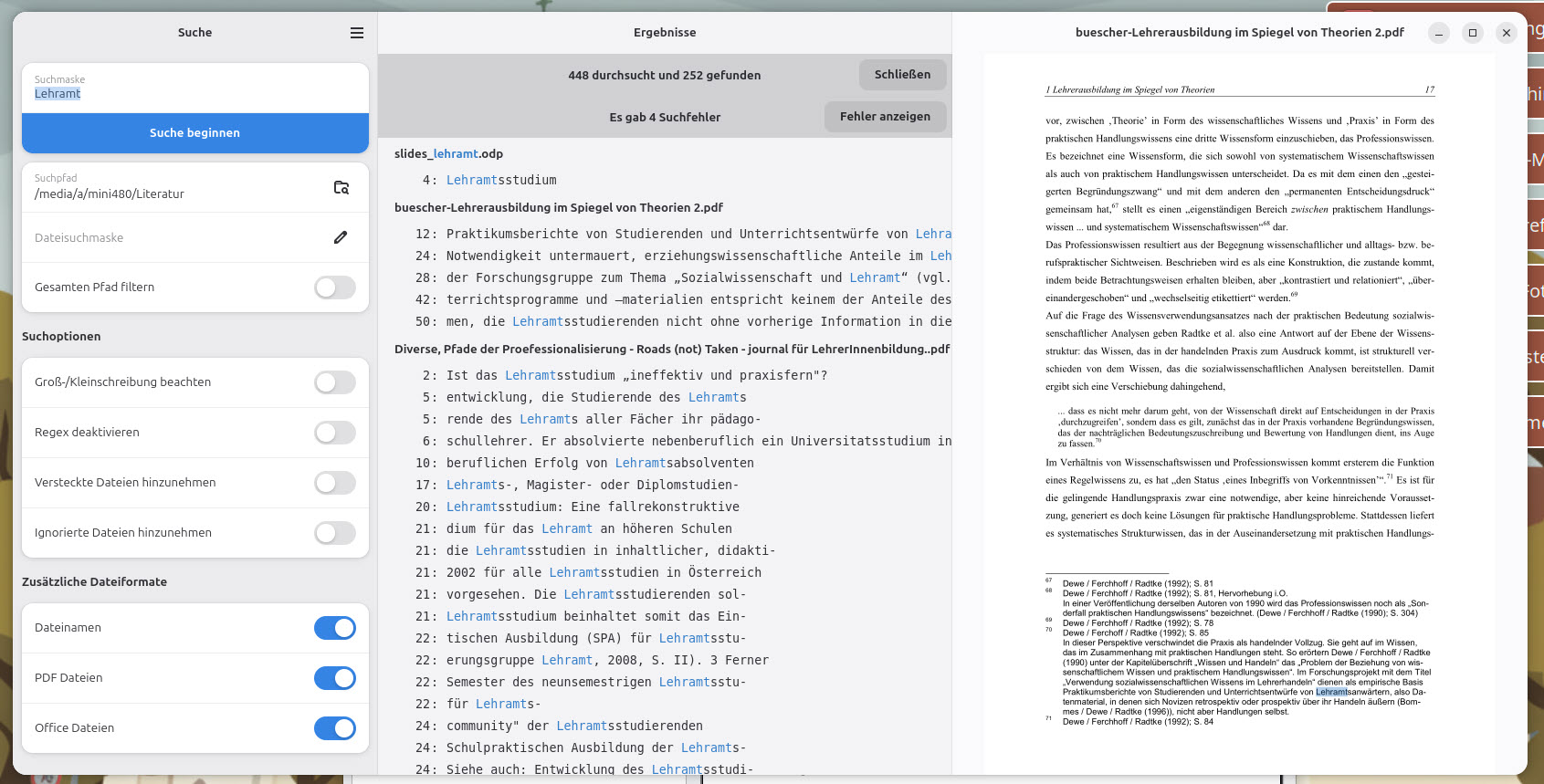
Sofern es sich um PDF-Dokumente handelt, wird zu jeder Fundstelle die Seite in einer Vorschau angezeigt - samt farblicher Markierung der Begriffe.
 Markierung der Fundstellen in der Vorschau
Markierung der Fundstellen in der Vorschau
Office-Dokumente werden auch durchsucht und aufgelistet, aber die Vorschau für diese Formate ist noch in Arbeit. Dafür wird z. B. bei Folien die Nummer jener Folie aufgeführt, die das Suchwort enthält. Ein Klick auf den Dokumententitel öffnet die Datei in der dazugehörigen Anwendung. Komplexere Anfragen können mit Regex-Suchen durchgeführt werden.
Alternativ lässt sich das Tool auch als blitzschnelle Suche nach Dateinamen nutzen:
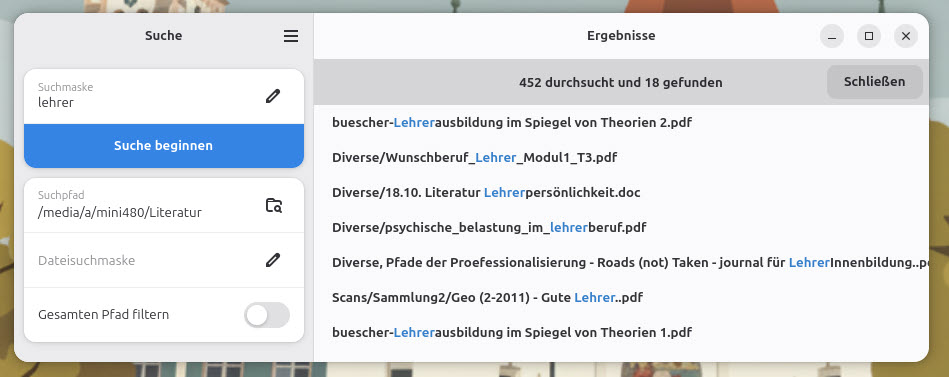
Suche nur innerhalb von Dateinamen
Prinzipiell erhält man mit Clapgrep ein grafisches Frontend für das Terminal-Tool ripgrep, das als extrem performantes Rust-Tool bekannt ist. In Zukunft soll es noch eine Textsuche in Bildern geben und Dateien im EPUB-Format sollen durchsuchbar sein.
Mir gefällt das Tool gerade für die gelegentliche Suche in einem Bestand und das kurze Nachschlagen einer Stelle, an die man sich verschwommen erinnert. Damit entfällt der "Pflegeaufwand" für Index-Aktualisierung, Vorab-Auswahl bestimmter Verzeichnisse usw. (Für ein systematisches Dokumentenmanagement nutze ich Paperless-ngx, aber das erfüllt dann völlig andere Aufgaben.)
Quellen:
Eigene Screenshots



Vielen Dank für den Hinweis auf das Tool! Genau so was suche ich gefühlt schon ewig. Ich brauche solche Volltextsuchen auch nur gelegentlich, aber wenn, dann ist die Not in der Regel groß, die passende Stelle zu finden ;) Ich hatte dafür früher recoll. Das ist in der Bedienung und in der Installation mit den ganzen Plugins komplexer. Gnome Files (nautilus) bietet ja auch eine Volltextsuche, aber halt ohne die hilfreiche Vorschau. Auch mag ich für solche Zwecke lieber GUI-Tools als CLI. Ich hoffe, sie fügen wirklich noch den epub Support hinzu. Dann wäre es perfekt für mich.
Das genialste Tool, dass ich in den letzten 3 Jahren ausprobiert habe. Danke für den Hinweis.
Eigentlich sollte für jedes wichtige Terminal CLI-Tool ein alternatives Frontend mit einer verständlichen und leicht zu bedienen GUI-Oberfläche existieren. Damit entfällt nicht nur der unangenehme Wechsel zwischen der Desktop & Terminal-Welt sondern man gewinnt in aller Regel auch einiges an Komfort und Übersichtlichkeit.
Habe gerne unter Debian Ihre Anregung aufgegriffen. Tatsächlich enorm was die APP findet. Sowohl im Text, Mail, PDF oder auch Titel eines Fotos. Nur lassen sich aus der Gefunden Liste heraus fast keine der Dateien öffnen. Die Fotodatei hat angeblich sowohl im Fotoprogramm und im Firefox angeblich einen Fehler. Im Dateiexplorer geht es aber anstandslos. Insofern eigentlich wenig brauchbar
Es wird das Dokument mit den darin enthaltenen Fundstellen gezeigt. Ein Klick auf den Dokumententitel öffnet sofort jedes Format. Eventuell meinst Du aber den direkten Sprung an die passende Stelle in einem Dokument? Das klappt nicht.
Das Thema "Volltextsuche" ist ein ziemlicher Dauerbrenner. In früheren KDE-Installationen gab es Nepomuk, aus dem Baloo hervorging. Eigentlich nutzt es im Prinzip Xapian. Aber mit Nepomuk hatte ich immer Probleme, die man erst mitbekommen hat, wenn man nichts gefunden hat. Bei Baloo gab es auch eine "schlechte" Phase, so dass ich das nur noch zur Dateinamen-Suche nutze, ohne Dateiinhalt.
DocFetcher fand ich eine Zeit lang spannend. Irgendein Witzbold auf einer meiner früheren Arbeitsstellen meinte, auf einem Netzlaufwerk alles nach Datum abzulegen, man findet das dann schon. Der hatte seinen "Index" vermutlich im Kopf, aber alle anderen standen da oder mussten ihn fragen. Da hat mir DocFetcher gute Dienste geleistet, weil es das auch unter Windows gibt.
Privat bin ich seit Jahren bei Recoll und kann nicht meckern. Starten, Ordner angeben, läuft. Das Tool sagt durch "missing" ja selbst, was fehlt. Einmal nachinstalliert und fertig. Auch einen Index-Dienst legt man fix an.
Richtig praktisch ist, dass es inzwischen (seit Plasma 6?) einen guten KRunner dafür gibt. Außerdem finde ich die Aufteilung von Index-Dateien super. Auf meinem Notebook läuft ein lokaler Dienst über lokale Dateien. Auf dem Server läuft ein eigener Dienst. Über "multiple indexes" kann ich diese anbinden und über meinen Gesamtbestand suchen. Es gäbe auch ein Webfrontend, das habe ich aber noch nicht angeschaut.
Es ist halt die Frage, wie man sucht. Wenn es nicht sehr oft ist, könnte man auf einen Index verzichten. Wenn man aber auch viele Dateien hat, wäre ein Index effektiver. Sobald der Grunddatenbestand mal steht, sind Aktualisierungen recht fix.