
Privat nutze ich ausschliesslich Linux. Im Haupterwerb (Teilzeitangestellter) muss ich Windows verwenden und in meinem Nebenerwerb nutze ich mehrheitlich Linux.
Nutzung im privaten Büro
Software (unvollständig)
- Ubuntu 20.04 Desktop
- Ubuntu 18.04 / 20.04 Server
- Firefox (seit es kein Netscape mehr gibt)
- Vivaldi (seit ein paar Wochen begeistert)
- Thunderbird (bisher versagt jeder andere Linux eMail-Client bei mindestens einem Killerkriterium)
- Typora (damit wurde auch dieser Aufsatz geschrieben)
- Libre Office
- GnuCash
- Recoll (Desktop-Suchmaschine)
- GIMP
- Visual Studio Code (nicht alles von M$ ist elend)
- Gnome Sudoku (für die kleine Abwechslung zwischendurch)
Hardware (unvollständig)
-
ASUS TUF A17, Ryzen 7, 32GB, 512GB SSD (mein mobiles Arbeitstier)
- SnapScan ix100
-
Shuttle XPC, i5, 16GB, 2x Dell 24" (mein stationäres Arbeitstier)
- Brother ADS2100
Workflows (unvollständig)
- Meine Dokumente organisiere ich bewusst ohne DMS, weil ich das Zeugs auch dann wieder finden möchte, wenn irgendwann nur noch eine DVD Scheibe vorhanden ist. Zu dem Zweck habe ich mir eine hierarchische Ordnerstruktur angelegt, welche die Dokumentklassen abbildet (Rechnungen, Bankbelege, Verträge, Haus, Versicherungen u.s.w.). Diese Ordner haben, falls sinnvoll Unterverzeichnisse (2019, 2020, 2021...).
- Für die Dokumentsuche verwende ich Recoll . Dieser Suchmaschine entgeht nichts!
- Thunderbird ist mit der Option "MAILDIR" installiert. Ausserdem arbeite ich intensiv mit "Archiven" in "Lokale Ordner". Alle Konten und "Lokale Ordner" befinden sich statt im Thunderbird-Profil in meinem "home/". MailDir wird sehr gut von Recoll unterstützt, womit die Suche ziemlich umfassen ist.
- Damit sich der Aufwand für das Befüllen der Dokument-Ordner in Grenzen hält, habe ich mir eine kleine Anwendung für das Scanning / Dokumentvalidierung geschrieben: Dokument Stapel werden gescannt und als Bilddaten (pro Seite) in einem tmp-Verzeichnis gespeichert (halbautomatisch als SANE Job). Danach werden aus dem Bild-Stapel die Dokumente zusammengesetzt und als durchsuchbare PDFs direkt in den Zielordner abgelegt. Die APP verwendet Tesseract 4 womit ich richtig gute Ergebnisse erziele. Die App kann die Seiten anordnen, die Zielordner sind konfigurier-/erweiterbar und man kann direkt (ohne Scanning) Bilddaten importieren.
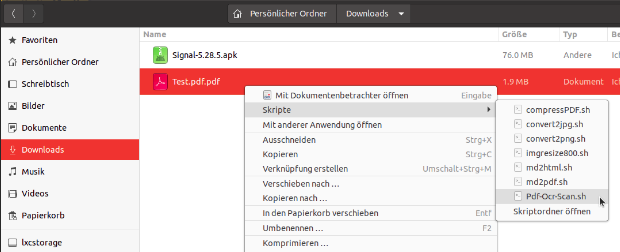
- Manchmal kriegt man z. B. per E-Mail PDFs, welche noch kein gescheites OCR erfahren haben. Dafür habe ich ein kleines Script in Nautilus hinterlegt welchem ich per Rechtsklick das betreffende PDF übergebe. Das Script ruft dann "OCRmyPDF" für diese Datei auf > alles ist gut.
- Weil sich bei mir privates und berufliches vermischt, verwende ich auch privat DokuWiki als Wiki/Info-Managementsystem. Aktuell sind knapp 1600 Seiten Dokumentationen und Anleitungen darin abgelegt.
- Weil ich auf mehreren Geräten arbeite, bin ich auf eine komfortable Synchronisation angewiesen. Das funktioniert robust mittels Nextcloud. Auf meinem Nextcloud-Server bin ich neben meinen Kunden einfach ein weiterer Mandant.
- Weil ich Nextcloud-Server für Kunden betreibe, laufen auch zwei Backup-Server. Somit ist das tägliche private Backup auch schon erledigt.
- Wie man weiter oben erkennen kann, kommt bei mir ab und zu ein Stück Software heraus. Ich bevorzuge zunehmend leichte Kost. Deshalb schreibe ich fast nur noch für Node.js. Meine bevorzugte IDE ist Visual Studio Code.



Danke, die beiden vorgestellten eigenen Apps klingen sehr interessant! Gibt’s die irgendow? Da musste ich allerdings zweimal schunzeln ;)
Danke - recoll und "maildir" nutze ich nun auch^^...
@gnulinux Hi Daniel habe gerade deinen Artikel gelesen.
Deine Workflow Info mit Recoll ist sehr interessant. Ich bin schon länger auf der Suche nach so einem Tool und werde es mal unter Linux Mint ausprobieren, es wird ja auch noch aktiv weiterentwickelt.
Dein Hinweis mit dem Rechtsklick für die Skripte in Dateimanager so wie dein selbstgeschriebenes Scanprogramm finde ich auch äußerst interessant.
Vielleicht kannst du mal ein Beitrag zu deiner Rechtsklick Skriptsammlung und wie man das in den Linux Dateimanager einbindet schreiben, und die OCR etc. Dateien zur Verfügung zu stellen, dann muss ich die Arbeit selber nicht noch mal tun.
Ich nutze selber auch eine Nextcloud von hosting.de, die sehr robust über Linux, Windows und Android alle meine Notizen, Aufgaben und Termine synchronisiert.
Mit Yunohost habe ich auch schon mal eine Nextcloud und ein WordPress-Blog testweise aufgesetzt.
Thunderbird nutze ich auch schon sehr lange, sehr gut ist für mich das es sehr gut auch die Aufgaben im Kalender darstellen kann, was auch sehr robust mit dem Nextcloud sync funktioniert.
Herzliche Grüße aus dem Norden Deutschlands.🎏
Danke für die Erwähnung von Maildir in Firefox. Das juckt bestimmt schon ein Jahrzehnt in meinem Kopf, wird direkt morgen umgestellt.
Danke, interessant und inspirierend
Hi Daniel
Danke für deinen interessanten Beitrag. Ich bin neu bei Linux und dein Beitrag hat mir das leben gleich ein wenig leichter gemacht. Ich würde gerne noch mehr erfahren zu den Skripten und wäre ebenfalls froh um ein paar Infos mehr zu den genutzten Programmen etc.
Lg aus der Schweiz^^