
Ich habe mich vor Kurzem dazu entschieden, Musik wieder zu kaufen, statt zu streamen. Das hat (für mich) zwar diverse Vorteile, bringt aber auch Nachteile mit sich, z.B. muss man sich - v.a. bei Rips von CD - selbst darum kümmern, dass die Metadaten der Dateien stimmen, damit Angaben wie Titel, Interpret, Album, Genre usw. korrekt angezeigt werden. Evtl. möchte man zusätzlich Informationen wie Songtexte oder das Cover-Art in den Dateien speichern. All das und noch mehr ist mit beets (Dokumentation) möglich.
Installation
beets steht als Terminal-Anwendung für diverse Linux-Distributionen, macOS und Windows zur Verfügung. Je nach Linux-Distribution ist es bereits in den Paketquellen des Paketmanagers enthalten. Um die aktuellste Version zu verwenden, empfiehlt es sich aber, die Installation über den Python-Paketmanager pip durchzuführen. Falls pip und Python sowie das python3-venv-Paket (zur Erstellung virtueller Python-Umgebungen) noch nicht installiert sind, lassen sich diese z.B. wie folgt installieren:
sudo apt install python3 python3-pip python3-venv
Anschließend sollte eine virtuelle Python-Umgebung (venv) erstellt werden:
python3 -m venv [Pfad zur neuen virtuellen Umgebung]
Die Python-Umgebung wird nun per source[Pfad zur virtuellen Umgebung]/bin/activate aktiviert (diese Aktivierung ist immer notwendig, bevor beets genutzt werden kann). Danach lässt sich beets per pip installieren. Wichtig ist bei diesem Schritt, sich bereits vor der Installation zu überlegen, welche Plugins man nutzen möchte (siehe Plugin-Übersicht), damit diese mitinstalliert werden. In meinem Fall möchte ich die Plugins lyrics, lastgenre, fetchart, embedart und convert verwenden, d.h. der Befehl zur Installation von beets muss lauten:
pip install beets[lyrics,lastgenre,fetchart,embedart,convert]
Konfiguration
Nach der Installation muss beets noch konfiguriert werden. Dazu muss die Datei ~/.config/beets/config.yaml erstellt werden. Sollte das Verzeichnis noch nicht existieren, muss auch dieses noch erstellt werden.
Die Datei config.yaml kann alternativ auch jederzeit über den Befehl beet config -e bearbeitet werden; der Pfad lässt sich über beet config -p anzeigen.
In der config.yaml müssen nun zunächst zwei Informationen hinterlegt werden: der Pfad zum Musik-Verzeichnis (hier soll die Musik nach dem Import gespeichert werden) und der Pfad zur beets-Datenbank. Letztere wird von beets selbst angelegt, sobald Musik in beets importiert wird (dazu später).
Beispiel:
directory: ~/Musik library: ~/Musik/musiclibrary.db
Plugin-Konfiguration
Möchte man Plugins verwenden, müssen diese zunächst aktiviert werden. Für die o.g. Plugins geschieht dies über folgenden Eintrag in der config.yaml:
plugins: lyrics lastgenre fetchart embedart convert
Für jedes Plugin stehen ggf. noch weitere Optionen zur Verfügung. Welche das sind, seht ihr, wenn ihr in der Plugin-Übersicht das entsprechende Plugin auswählt. Die config.yaml sieht nun also wie folgt aus:
directory: ~/Musik library: ~/Musik/musiclibrary.db
plugins: lyrics lastgenre fetchart embedart convert
Import von Musik
Vor dem Import empfiehlt es sich, Titel nach Album in jeweils einem eigenen Verzeichnis zu sortieren, da beets davon ausgeht, dass ein Verzeichnis ein Album darstellt. Das mache ich schon nach dem Rippen von CD.
Anschließend könnt ihr die Titel im entsprechenden Verzeichnis wie folgt importieren:
beet import [Pfad zum Import-Verzeichnis]
beets gleicht beim Importvorgang das entsprechende Album mit den Einträgen in der Musicbrainz-Datenbank ab und schreibt basierend darauf die Meta-Informationen in die Datei. Es kann passieren, dass beets den falschen Eintrag zuordnet oder es keinen passenden Eintrag gibt. Sollte die Wahrscheinlichkeit einer Übereinstimmung zu niedrig sein, werdet ihr gebeten, den Import-Vorgang zu bestätigen oder einen anderen Eintrag auszuwählen:
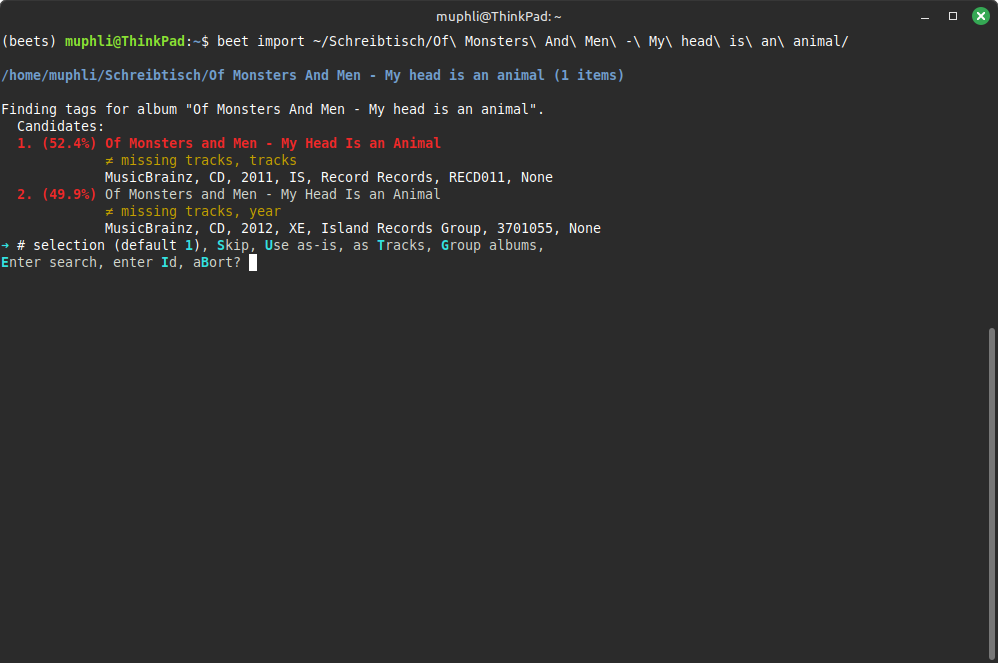
Ist der Import erfolgreich, werden die Titel standardmäßig in das in der Konfigurationsdatei angegebene Musikverzeichnis (directory) kopiert (das kann über die config.yaml aber auch geändert werden).
Über den Parameter -t könnt ihr beets zwingen, vor jedem Import eine Bestätigung einzuholen, um auf Nummer sicher zu gehen. Der Befehl lautet dann:
beet import -t [Pfad zum Import-Verzeichnis]
Konvertieren von Musik
Über den Befehl beet convert lassen sich die Musiktitel in ein anderes Format konvertieren. Standardmäßig wird in .mp3 konvertiert. Ihr solltet in der config.yaml dazu auf jeden Fall auch noch ein Ausgabeverzeichnis für die konvertierten Titel angeben. Das geht wie folgt:
convert: dest: [Pfad zum Ausgabeverzeichnis]
Weitere Funktionen
Dieser Artikel kratzt nur an der Oberfläche. beets kann noch viel mehr, z.B. könnt ihr Abfragen auf eure Musikbibliothek fahren, um alle Titel eines bestimmten Jahres, Genres usw. zu filtern. Ihr könnt auch die Art, wie beets Musik über Verzeichnisse sortiert, ändern oder Musik automatisch importieren lassen. Es lohnt sich dazu auf jeden Fall ein Blick auf die Seite "Advanced Awesomeness" in der Dokumentation.
Titelbild: https://commons.wikimedia.org/wiki/File:Musik-CDs.jpg
Quellen:
https://beets.io/
https://beets.readthedocs.io/en/stable/



Wichtig finde ich noch, dass man beim Importieren der Musik unterscheidet, ob es sich um Alben oder Einzeltitel (dann mit "beet import -s" arbeiten) handelt. Ansonsten meckert beets nämlich wegen fehlender Tracks rum etc.
Guter Punkt! Vielen Dank für die Ergänzung!
Als GUI Version wäre es interessant aber so viel zu umständlich
Ist nicht ganz so gut wie beets, aber da kann man exfalso nehmen. Das kommt mit dem Quodlibet Audioplayer, der übrigens auch ziemlich gut ist.
Kann ich verstehen, vielleicht ist das von Svendler unten erwähnte MusicBrainz Picard eine interessante Alternative für dich?
Hallo zusammen,
der Mehrwert von beet erschließt sich mir persönlich nicht ganz – zumindest nicht in meinem Anwendungsfall.
Ich nutze bewusst keine Streamingdienste wie Spotify & Co., da ich Musik lieber besitze und unabhängig von externen Plattformen und deren Geschäftsmodellen bleiben möchte. Das bedeutet natürlich, dass ich Musik-CDs selbst digitalisiere. Da ich regelmäßig komplette Sammlungen aufkaufe, rippe ich im Grunde laufend – und das schon seit 1996.
Nach dem Rippen (ins OGG-Vorbis-Format) lade ich die Dateien in MusicBrainz Picard, um sie sauber zu taggen. Klar, ich könnte das wie bei beet auch meinem Musikserver (Jellyfin) überlassen – aber dann habe ich keinerlei Kontrolle über das Ergebnis. Da ohnehin die MusicBrainz-Datenbank genutzt wird, verstehe ich nicht ganz, warum man den Zwischenschritt über Picard weglassen sollte.
Mit Picard sehe ich auf einen Blick, welche Metadaten fehlen, kann direkt zur entsprechenden Seite bei MusicBrainz springen und dort Einträge ergänzen oder korrigieren. So trage ich aktiv zur Verbesserung der Datenbank bei. Alben oder Singles, die komplett fehlen, erfasse ich direkt aus Picard heraus mit vollständigen Metadaten und Cover – und der nächste Nutzer freut sich über vollständige Informationen. Bei vielen CDs ist dagegen keine Nacharbeit nötig.
Sind die Tags vollständig, übertrage ich die Sammlung auf meinen Jellyfin-Server – und streame sie dann doch wieder, allerdings meine eigene Musik, komplett unabhängig und vor allem auf all meine Geräte.
MusicBrainz Picard kannte ich tatsächlich nicht. Ich habe es (noch) nicht ausprobiert, es scheint aber eine interessante Alternative zu sein. Ich bin auf beets durch die Dokumentation von Tangara aufmerksam geworden, habe es ausprobiert und Gefallen daran gefunden. Du hast natürlich vollkommen recht: Wenn Picard zum Einsatz kommt braucht es beets natürlich nicht. beets ist letztlich ein anderer Weg zum gleichen Ziel.
Für dich scheint es keine Mehrwert zu geben. Wer aber nicht schon beim Digitalisieren so ordentlich arbeitet, für den bietet beets schon eine gewaltige Erleichterung.
Keiner will zigtausend Tags überprüfen. Meine Sammlung it in Ordner sortiert und fertig
Viel zu kompliziert. Wenn man kein Nerd ist oder werden will, nimmt man besser etwas aus dem repo mit gui.