Mittels des Programms GNOME Simple-Scan (Deutscher Name "Dokument-Scanner") lassen sich Dokumente einscannen und als PDF ablegen (funktioniert auch unter KDE Plasma).
Diese sind aber leider per se nicht nach Text durchsuchbar. Dazu muss mittels OCR eine Text-Erkennungs-Schicht in das Dokument eingebettet werden. GNOME Simple-Scan bringt diese Fähigkeit nicht von Hause aus mit, aber die eingescannten Dokumente lassen sich beim Speichern per optionalen Kommandozeilen-Aufruf an ein Programm zur Nachbearbeitung übergeben, im Artikel wird das Kommandozeilen-Tool OCRmyPDF verwendet.
GNOME Simple-Scan und OCRmyPDF installieren
Das Paket Simple-Scan über die Paketverwaltung aus den Standard-Repositories installieren. Das Paket ocrmypdf kann in Arch und Manjaro aus dem AUR installiert werden. Dazu muss ein AUR-Helper wie YAY oder Paru auf dem System installiert sein. (Genereller Hinweis: Bitte AUR-Sicherheitshinweise bei der Verwendung des AUR beachten.)
In der Shell sieht das so aus:
Manjaro:
pamac install simple-scan
yay ocrmypdfArch:
sudo pacman -S simple-scan
yay ocrmypdfBei der Installation von ocrmypdf unbedingt die optionale Deutsche OCR-Spracherkennung tesseract-data-deu (und am besten die oft verwendete Sprache Englisch tesseract-data-eng) mitinstallieren lassen!
GNOME Simple-Scan konfigurieren
Unter Einstellungen die Nachbearbeitung einschalten und ein Skript hinterlegen, welches im nächsten Schritt erzeugt wird, z.B. /home/user/.local/bin/ocrmypdf.sh (Name und Ort der Datei sind frei wählbar, sie muss als Shell-Script aber natürlich ausführbar gemacht werden und an dem hier angegebenem Ort mit dem angegebenem Namen erzeugt werden.)
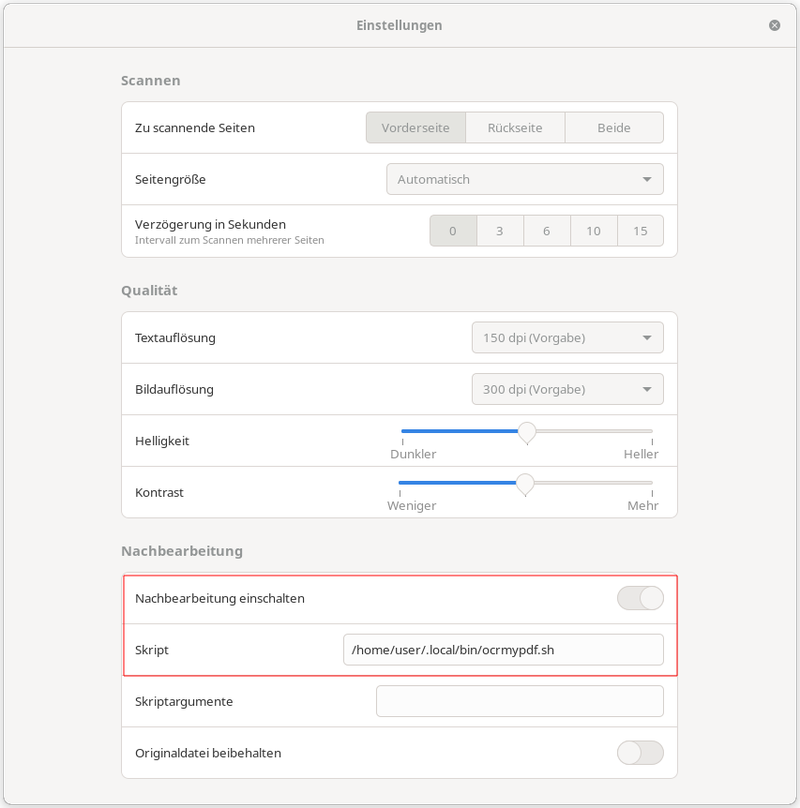
Script zur OCR-Erkennung erstellen
Hier wird das so eben eingescannte Dokument von der GNOME Simple-Scan GUI beim Druck auf "Speichern" an ocrmypdf übergeben. An 4. Stelle der Kommandozeilen-Argumente befindet sich der verwendete Dateiname (dies habe ich nicht dokumentiert gefunden, sondern rausgetraced; wer eine entsprechende Doku findet, gerne Hinweis in den Kommentaren). Wichtig ist ebenfalls die Spezifikation der zu verwendeten Texterkennungs-Sprache, in dem Fall sind das Englisch und Deutsch:
Grob gesagt, ist die Syntax für OCRmyPDF:
ocrmypdf
(Weiteres lässt sich mit ocrmypdf --help anzeigen.)
Ergo muss nun eine neue Shell-Script Datei erzeugt werden, z.B. /home/user/.local/bin/ocrmypdf.sh mit folgendem Inhalt:
#!/usr/bin/env bash
/usr/bin/ocrmypdf --LANGUAGE eng+deu "$4" "$4"In o.g. Beispiel werden Englisch und Deutsch erkannt und die ursprüngliche PDF-Datei wird mit der PDF-Datei ersetzt, die die OCR-Daten enthält (dies könnte entsprechend geändert werden, z.B. in "$4"_output.pdf o.ä.).
Das erzeugte Dokument kann nun im PDF-Betrachter der Wahl nach Text durchsucht werden. (Dies funktioniert z.B. direkt auch in der Content-Suche im Dolphin Dateimanager, andere Dateimanager wurden nicht getestet.)
Quellen:



Ich bevorzuge gscan2pdf (https://software.manjaro.org/package/gscan2pdf). Das bringt bereits OCR und viele weitere Funktionen mit.
Danke, werde ich mir anschauen.
Wollte ich just auch einwerfen wo ich den Artikel gesehen habe. Wenn, dann nutze ich auch gscan2pdf, allerdings fehlt mir die Ausgabe als PDF/A. Vielleicht weiß wer wie ich PDF/A als Output von gscan2pdf erhalten kann. Ansonsten ist das ein Stück spitzen Software die super funktioniert. Eigentlich hatte ich meinen Epson WorkForce ES-580W Dokumenten Scanner so ausgewählt, dass ich ohne Software via Touch auf ein FTP oder SMB Laufwerk scannen kann (funktioniert super), aber diese sind zwar als PDF/A, aber nicht durchsuchbar gescannt. Daher nutze ich ab und an gscan2pdf wenn es durchsuchbar sein soll. Ist aber dann nicht PDF/A. Eine Kröte ist immer zu schlucken. Also wenn wer weiß wie gscan2pdf ein PDF/A am Ende aus gibt, dem wäre ich sehr verbunden.
Hallo Christopher: Laut dem cookbook zu ocrmypdf auf readthedocs.io (https://ocrmypdf.readthedocs.io/en/latest/cookbook.html) produziert ocrmypdf standardmäßig PDF/A Dokumente. Will man das nicht, muss man einen weiteren Parameter angeben "--output-type pdf" um ein gewöhnliches PDF zu erhalten. Bei meinen Test stand in den Eigenschaften der Doikumente als Format PDF/A - 2b. Simple-Scan/Dcoument Scanner spechert Scans ansonsten im PDF-1.3 Format. Gruß, Klaus
Das würde aber nur mit Simple Scan und der Weiterleitung funktionieren. gscan2pdf produziert standard mäßig nur PDF files und kein PDF/A. Gibt es also eine Möglichkeit bei gscan2pdf das auch nach ocrmypdf weiter zu leiten oder mit der standard genutzten OCR Engine ein PDF/A zu erzeugen?
Auch ich suche aktuell nach einer geeigneten Software, um auch OCR mit PDF-A zu handlen. Daher bin ich über den hier vorgestellten Ansatz sehr dankbar und testen ihn. Das Tool ocrmypdf hatte ich vorher bereits getestet, nur nicht das geeignete Scantool, welches dieses aufrufen kann.
Auf meiner Suche bin ich auch über einen sehr interessanten Artikel bzgl ZUGFeRD gestolpert, welchen man sicher auch gut mit ocrmypdf abbilden kann (https://ghostscript.com/blog/zugferd.html).
Der erste Ansatz würde vermutlich in etwas so aussehen: ocrmypdf -l eng+deu --color-conversion-strategy RGB --force-ocr --output-type pdfa-3 scanned.pdf scanned_ocr_pdfa3.pdf
Lg Stefan
Frage, warum benutzt du hier nicht beides mal yay?
yay -S simple-scan yay ocrmypdf
Weil das AUR potenziell gefährlich ist verwende ich so viel wie möglich aus den offiziellen Repos.
Das AUR muss nicht immer benutzt werden, wenn Garuda verwendet wird oder die Paketquelle installiert von Chaotic https://aur.chaotic.cx/ Bei mir hat es den Admin-Aufwand stark reduziert
Ich verwende das chaotix-AUR auch, aber das mag ich nicht in einer Installation von Scanner-Software beschreiben; wäre ein eigener Artikel, magst Du...? Dann würde ich auf drauf verlinken...
> funktioniert auch unter KDE Plasma
Oder man verwendet dort skanlite ;)
Skanlite kann kein OCR, oder ich habe es nicht gefunden!? Mit dem verwendeten Scanner (Brother ADS-1700W) hab ich es nicht mal geschafft mehrere Seiten in einem Rutsch einzuscanner. Daher die GNOME/GTK Tools.
Moin, ich benutze dazu gerne Paperwork (https://www.openpaper.work/de/), ja ist eigentlich eine Dokumentenverwaltung, aber genau dabei brauche ich eben durchsuchbare PDFs.
LG Jörg
Ja, paperwork habe ich mir auch angeschaut und es macht was es soll. Einen Ticken mehr ist paperless-ngx, dass lässt sich aber nur als Docker wirklich vernünftig installieren. Allerdings steigt mit allen Lösungen wieder der administrative Aufwand. Für mich habe ich erst einmal entschieden alles in einer eigenen Verzeichnis Struktur abzulegen und zu organisieren. Damit bin ich von jeglicher Software unabhängig und habe keinen weiteren administrativen Aufwand. Zumal, fällt eine Software weg (Projekt wird beendet, ...), dann habe ich einen Haufen unsortierter Dokumente. Abhängigkeiten! Wenn die Anzahl der zu verwaltenden Dokumente mehr wird, dann bin ich mir auch sicher, dass ohne eine Dokumenten Verwaltung das sehr schwierig wird. Für zu Hause denke ich aber das es nicht mehr sein muss. Zur Not lassen sich alle meine Dokumente später auch erfassen.
Ja, da hast du einen Punkt ;-) - ist eine gute Anregung meinen Workflow mal zu überdenken.
Du kannst in paperless ngx das Format der Dokumente mittels Platzhaltern definieren, so dass die Ordnerstruktur für dich erstellt wird. Dadurch sollte es keine Probleme geben, wenn in Zukunft ein anderes DMS (oder keins) genutzt werden soll.
https://docs.paperless-ngx.com/advanced_usage/#file-name-handling
Danke für die Idee, Prof. P! Ich benütze Simple-Scan/Document Scanner sehr viel, da es für meine Bedürfnissee einfach gut funktioniert. Ich habe dein Skript ein bisschen angepasst, so dass es auf meinem System (Xubuntu) läuft und auch ein kleines Problem umseilt, so dass nicht wahllos alle Dateiformate OCRt werden.. Hier das Skript: '''
!/usr/bin/env bash
if [[ $3 == *.pdf ]] then /usr/bin/ocrmypdf -l eng+deu+nld $3 $3 fi ''' $4 hat bei mir nicht funktionert. Bei mir ist der Dateiname der 3. Parmater.
Meine Version checkt erst an Hand der Dateiendung, ob es sich um ein PDF handelt, bevor ocrmypdf aufgerufen wird. Ohne diese Kontrolle waren meine als JPG oder PNG abgespeicherten Scans nicht mehr lesbar.
Bei mir hat dein Skript nur mit folgender Anpassung funktioniert:
!/bin/bash
if [[ "$3" == *".pdf" ]]; then /usr/bin/ocrmypdf -l eng+deu --force-ocr "$3" "$3" fi
Danke für den Artikel, der mir wichtige Impulse geliefert hat.
Hier der gewünschte Hinweis zur Doku. Dort sieht man welches Argument für die Dateinamen verwendet werden muss und bekommt sogleich einen Test auf PDF mime_type mitgeliefert: https://gitlab.gnome.org/GNOME/simple-scan/-/blob/master/src/simple-scan-postprocessing.sh
Laut OCRmyPDF Doku gibt es kein Argument --LANGUAGE. Es muss "-l" oder "--languages" verwendet werden.
Nice one, saved me some time. It's $3 btw.
Das skript funktioniert bei mir (Ubuntu 22.04) nicht mehr. Hier hat jemand mit den Ansatz aufgegriffen und leicht erweitert: https://gist.github.com/marcosrogers/fc0250a52490e92ab8293bd781231a7e?permalink_comment_id=5561738