
Speichermedium voll? Dann ist das Werkzeug rmlint wie für euch gemacht, da es beim Deduplizieren von Dateien hilft. Darunter versteht man die Identifikation von mehrfach vorhandenen, aber gleichen Dateien auf einem Speichermedium. Das Tool findet jedoch mehr als Duplikate, nämlich:
- Doppelte Dateien und Verzeichnisse
- Nicht entpackte Binärdateien
- Kaputte Symlinks
- Leere Dateien
- Rekursive leere Verzeichnisse
- Dateien mit defekter Benutzer- oder Gruppenkennung
Den Namen rmlint könnte man frei mit "Flusen entfernen" übersetzten (remove lint). Ein Linter ist das Tool damit nicht, weil sich dieser Begriff auf die Codeanalyse statt auf die Dateianalyse bezieht, aber das ist nur halb-interessant. Das Kommandozeilen-Werkzeug rmlint findet sich in den Repositories der gängigen GNU/Linux-Distributionen und ist somit schnell installiert, z.B. mit pamac install rmlint bei Arch-basierten Systemen.
Nach der Installation kann man rmlint bedenkenlos in einem Home-Unterverzeichnis starten, da es keine Dateien löscht, sondern vorerst die Kandidaten ermittelt. Falls sich im gewählten Unterverzeichnis nicht zu viele Daten befinden, könnt ihr das Werkzeug entweder mit rmlint oder rmlint -g laufen lassen. Die erste Variante wird eine lange Liste mit rm und ls Zeilen ausspucken und anschliessend eine Zusammenfassung anzeigen. Beim zweiten Befehl kommt ein Fortschrittsbalken und die Zusammenfassung.
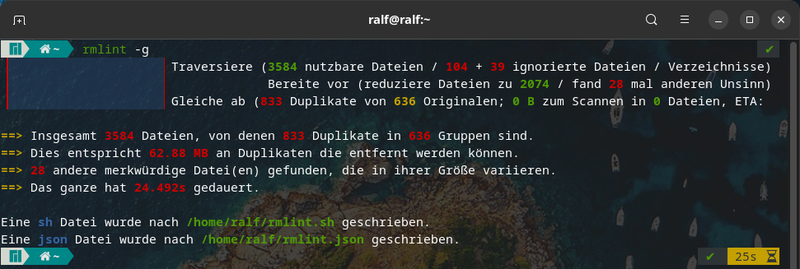
Die Befehle zum tatsächlichen Entfernen der Duplikate schreibt rmlint in die Datei rmlint.sh und die reinen Daten in die Datei rmlint.json. Nun hat man zwei Möglichkeiten: entweder man führt das Shell-Skript aus, oder verwendet die Daten aus der JSON-Datei für eine eigene Verarbeitung.
Aber Achtung! Man sollte dem Shell-Skript auf keinen Fall blind vertrauen; nicht weil es nicht funktionieren würde, sondern weil es womöglich Duplikate gefunden hat, die man bewusst erzeugt hat, oder die in verschiedenen Kontexten tatsächlich als Duplikat benötigt werden. Ausserdem hilft ein Blick ins Handbuch von rmlint, weil die Funktionsweise und die Optionen des Werkzeugs dort gut erklärt werden.
Titelbild: https://pixabay.com/photos/lint-entfusseln-unwinds-dust-pill-2137161/



Doppelte Daten suche und finde ich mit czkawka. Könnt ihr vielleicht mal ein Blick drauf werfen und vergleichen.
https://github.com/qarmin/czkawka
Fslint ist mein Favorit und leistet seit Jahren gute Dienste. Rmlint ist aber auch gut. Und soweit ich weiss gibt es für Ubuntu noch shrudder als grafisches Frontend zu rmlint.
Hast du von der aktuellen Binärgewitter folge? Ich kann da sehr Dupeguru empfehlen. Der kann nämlich mehr als nur einfache duplikate finde. https://github.com/arsenetar/dupeguru
Ein paar Beispiele und Erklärung der einzelnen Optionen wären hilfreich gewesen. Nach welchen Kriterien in welcher Reihenfolge 'sucht' rmlint nach Dublikaten? Kann man bestimmte Dateien auschließen und wenn dann wie? Gibt es eine grafische Benutzeroberfläche oder muss man in der Konsole arbeiten? Fragen über Fragen...