
Speech-to-Text gibt es schon seit den 90er-Jahren. Doch so richtig überzeugen konnte die Funktion in den vergangenen 30 Jahren nicht. Entweder waren die Ergebnisse zu schlecht, oder es war zu teuer, nicht schnell genug, oder verschob das gesprochene Wort auf Dienstleister, bei denen man seine Stimme und Inhalte nicht haben wollte.
Für Speech-to-Text gibt es viele nützliche Anwendungsfälle:
- Barrierefreiheit
- Texte diktieren
- Transkription
- Steuerung
Mit der Anwendung Speed of Sound wird ein neuer Versuch gestartet, diese Aufgabe für den alltäglichen Gebrauch nutzbar zu machen. Hier sind die wichtigsten Fakten, die euch zu dieser Anwendung interessieren könnten:
- Offline-Transkription direkt auf dem Gerät, unterstützt von Whisper, Parakeet, Canary und weiteren Modellen. Es verlassen keine Daten dein Gerät.
- Mehrere Aktivierungsmöglichkeiten: Klicken auf die Schaltfläche in der App, Verwenden einer globalen Tastenkombination oder Steuern der App über die Taskleiste.
- Eingabe des Ergebnisses direkt in jede aktive Anwendung, mit Unterstützung für X11 und Wayland.
- Mehrsprachige Unterstützung mit spontan umschaltbaren Haupt- und Sekundärsprachen.
- Funktioniert sofort mit einem integrierten mehrsprachigen Whisper-Modell. Zusätzliche Modelle können direkt in der App heruntergeladen werden, um die Genauigkeit und Sprachabdeckung zu verbessern.
- Optionale Textoptimierung mit LLMs (Anthropic, Google, OpenAI), mit Unterstützung für benutzerdefinierten Kontext und Vokabular.
- Unterstützt selbst gehostete Dienste wie vLLM, Ollama und llama.cpp (Cloud-Dienste werden unterstützt, sind aber nicht erforderlich).
Das sagt die (übersetzte) Feature-Liste von Speed of Sound.
Was ist das?
Wie ihr es von mir kennt, trompete ich nicht einfach irgendwelche Meldungen heraus, sondern teste die Anwendungen, damit ihr wisst, worauf ihr euch einlasst. Glücklicherweise ist Speed of Sound (SoS) als Flatpak verfügbar, wodurch die Installation denkbar einfach und sicher ist (Container).
Nach der Installation startet man SoS und sieht dieses Fenster:
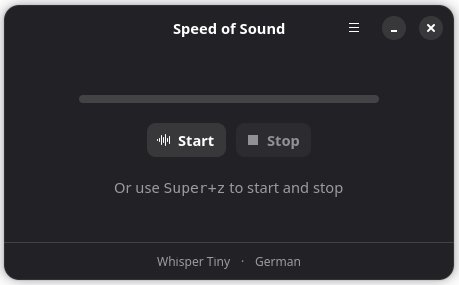
Dort kann man die Aufnahme starten und stoppen. Das geht auch mit der Tastenkombination Super+z, die man in den Einstellungen (Hamburger-Menü) ändern kann. Ausserdem wird offenbart, dass das kleine Whisper LLM von OpenAI (Whisper Tiny) für die Übersetzung von Sprache zu Text verwendet wird. Die Sprache habe ich bereits auf 'German' umgestellt.
You got me at OpenAI.
Halt, Whisper kommt von OpenAI, wird jedoch bei SoS lokal ausgeführt. Euer Gelaber verlässt nicht den Rechner, falls man dem Entwickler Antonio Zugaldia Glauben schenkt. Doch was ist Whisper?
Whisper ist ein universell einsetzbares Spracherkennungsmodell. Es wurde anhand eines umfangreichen Datensatzes mit vielfältigen Audioaufnahmen trainiert und ist zudem ein Multitasking-Modell, das mehrsprachige Spracherkennung, Sprachübersetzung und Sprachidentifizierung durchführen kann.
Ausprobiert
Nach der Installation von SoS startet man das Werkzeug und wechselt zu einer Anwendung, in der der aufgenommene Text eingefügt werden soll. Ich habe den GNOME-Texteditor dafür verwendet. Zu Testzwecken spreche ich den Anfangstext dieses Artikels ein. Um die Aufnahme zu starten/stoppen, drückt man SUPER+z. Hier seht ihr das Ergebnis:
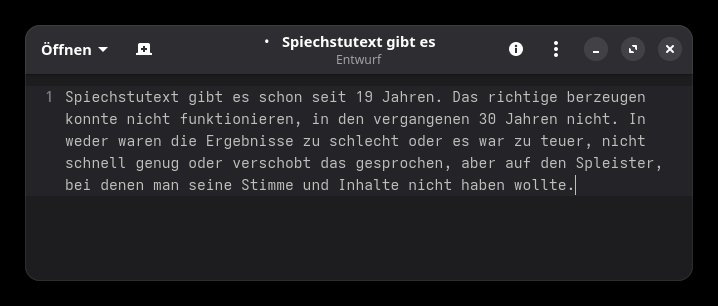
Je nach Länge des Textes, dauert es eine Weile, bis das Ergebnis erscheint. Beim oben gezeigten Beispiel musste ich ca. 10 Sekunden warten, bis der Text im Editor erschien. Ich habe mit dem eingebauten Notebook-Mikrofon aufgenommen. Ausserdem lief im Hintergrund der Fernseher. Das ist keine Entschuldigung, sondern entspricht einer üblichen Situation.
Hier ist ein zweiter Test mit einem einfacheren Text und ohne TV-Geräusche im Hintergrund:
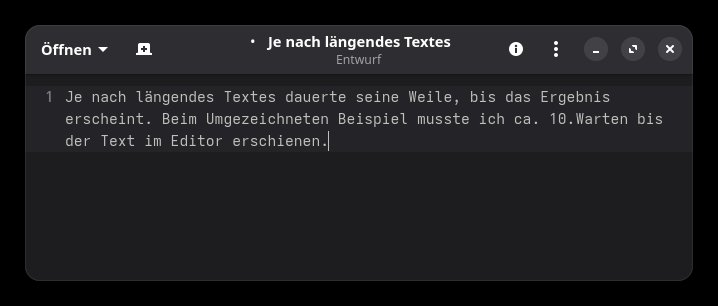
Na ja, die Ergebnisse überzeugen nicht, wohl aber die Bedienung, zumal die Tastenkombination für die Aktivierung angepasst werden kann. Bei den oben gezeigten Beispielen kam das Modell "Whisper Tiny" zum Einsatz, welches die Standardeinstellung von SoS ist. Doch die Anwendung bietet ca. 20 andere LLMs an, die alle lokal installiert werden:
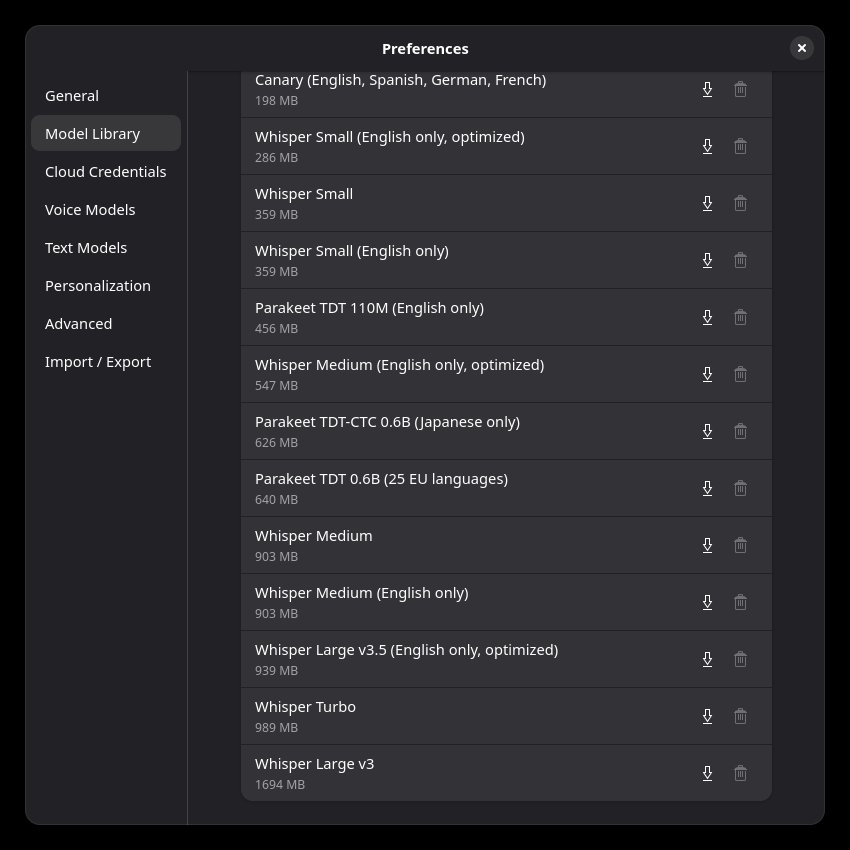
Dicke Hose
Aus Interesse, installiere ich das knapp 1 GB grosse Modell Whisper Turbo, um zu testen, ob sich damit bessere Ergebnisse erzielen lassen. Mit einer starken Internet-Verbindung (1 GB) ist das Modell in ca. 10 Minuten heruntergeladen und für die Verwendung in SoS vorbereitet. Alle Tests habe ich auf einem Tuxedo Infinity Book mit i7-CPU, 16 GB RAM und integrierter Intel Iris GPU durchgeführt. Bevor ihr einen auf dicke Hose machen könnt, müsst ihr das neue Modell auswählen:
Hier ist das Ergebnis mit Whisper Turbo (wie zuvor mit TV-Hintergrundgeräuschen und dem jämmerlichen Notebook-Mikrofon):
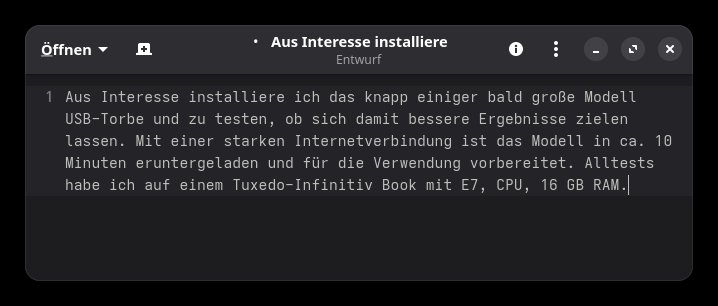
Tja, auch nicht viel besser als mit dem wesentlich kleineren Modell. In der Anwendung Speed of Sound (SoS) gibt es viele weitere Einstellungen. So kann man auch auf Cloud-basierte LLMs zugreifen, sofern man die nötigen API-Keys hat.
Fazit
In diesem Artikel ging es mir darum, wie gut lokale LLMs funktionieren und wie einfach sie bedienbar sind. Die Bedienung von SoS ist über alle Zweifel erhaben. Die Anwendung ist schnell installiert, sehr einfach zu bedienen und konfigurierbar, ohne zu überfordern.
Vom Ergebnis halte ich nicht viel. Selbst mit der 'dicken Hose' liefert SoS keine zufriedenstellenden Ergebnisse. Hinzukommt, dass man auf die Transkription von Sprache zu Text – auch bei kurzen Texten – lange warten muss. Das mag flotter gehen, falls man eine potente Grafikkarte hat.
Letztlich ist der Korrekturaufwand grösser, als der Gewinn. Das gilt nicht nur für Speed of Sound, sondern zieht sich wie ein roter Faden durch die meisten KI-Chatbots.
Titelbild: https://www.speedofsound.io/assets/logo-square-512.png
Quellen:



{kind=link}
Kann sein, dass das Programm schlecht funktioniert, kann aber auch sein, dass du einfach undeutlich sprichst 😁
Du kennst doch Ralf aus dem Podcast. Er spricht vorbildlich und ist selbst mit doppelter Abspielgeschwindigkeit noch sehr gut zu verstehen.
Also meine Ergebnisse mit Futo Keyboard für Android, das auch auf dem Whisper-Modell aufsetzt (für Deutsch habe ich die Multilingual-74-Variante mit gut 80 MB im Einsatz), sind deutlich akkurater mit viel weniger Fehlern. Auch mit mehreren anderen Sprachen, die ich garantiert nicht alle akzentfrei spreche, klappt das wirklich gut. Das Handy ist ein Redmi Note 8T mit /e/ OS, also leistungsmäßig garantiert nicht der Hammer. Die Transkriptionen erscheinen nach nur wenigen Sekunden für einen längeren Satz.
Vielleicht liegt es ja am verwendeten Laptop-Mikrofon – bei manchem Geräten sitzen die direkt am Lüfter.
Ich nutze seit einigen Monaten Handy und bin erstaunt, wie gut es funktioniert - auch mit dem billigen internen Laptop Mikrofon, aber dafür ohne Hintergrundgeräusche.
Vielen Dank für den Tipp. Ich habe "Handy" ausprobiert und bin beeindruckt. Mit dem Standardmodell Parakeet V3 habe ich bisher keinen Fehler und die Geschwindigkeit ist viel schneller als bei meinem Whisper-Modell bei Speechnote.
Mein Eindruck ist, dass das Modell "Canary" (200MB) am besten funktioniert. Auch mit 4GB RAM sind die Ergebnisse noch zufriedenstellend schnell. Zum Vergleich mit Whisper Turbo:
"Aus Interesse installiere ich das knapp ein Gigabyte große Modell Oespaturbo , um zu testen , ob sich damit bessere Ergebnisse erzielen lassen . Mit einer starken Internetverbindung ein Gigabyte ist das Modell in circa zehn Minuten heruntergeladen und für die Verwendung in S U S vorbereitet . Alle Tests habe ich auf einem Tuxedo Infinitbook mit I C P U und Gigabyte Ram und integrierte Intel Iris G U durchgeführt . "
Ich habe "Notely Voice" von FDroid auf meinem Smartphone (Pixel 8, GrapheneOS). Die Offline-Übersetzung der Notizen mit dem "dicken" Multi-Sprachen-Modell (ca. 0,5 GB) finde ich erstaunlich gut. Basiert ebenfalls auf "OpenAI Whisper". Hier mal der Artikelteil eingesprochen (beim Wort "Dienstleister" habe ich genuschelt/fehlbetont):
"Speech-to-Text gibt es schon seit den 90er Jahren, doch so richtig überzeugen konnte die Funktion in den vergangenen 30 Jahren nicht. Entweder waren die Ergebnisse zu schlecht, oder es war zu teuer, nicht schnell genug oder verschob das gesprochene Word-of-Teams-Leister, bei denen man seine Stimme und Inhalte nicht haben wollte. Für Speech-to-Text gibt es viele nützliche Anwendungsfälle, Barrierefreiheit, Texte-Diktieren, Transkription, Steuerung. Mit der Anwendungsbeat-off Sound wird ein neuer Versuch gestartet, diese Aufgabe für den alltäglichen Gebrauch nutzbar zu machen. Hier sind die wichtigsten Fakten, die euch zu dieser Anwendung interessieren könnten."
1-2 Fehler, davon einer der dem Modell natürlich unbekannte Name des Programms. Und das bei deutsch-englischem Sprachmix bzw. Fachsprache - finde ich erstaunlich gut. Die Zeichensetzung ist nicht eingesprochen, sondern vom Modell gesetzt. Es ist natürlich keine Live-Übersetzung, die Transkription dauerte ca. 25 Sekunden, auch das finde ich für ein nicht mehr brandneues Mobilgerät höchst akzeptabel.
Das ist jetzt auch kein Einzelfall - Wiederholung brachte exakt den selben Text aus der Audiodatei zum Vorschein und andere Sprachnotizen klappten bisher ebenfalls gut. Das Programm ist so gestaltet, dass man die Audiodatei mit behält, so dass man im Zweifel auch nachhören kann, wenn man die Fehler nicht gleich ausbessert.
Die gleichen Erfahrungen habe ich auch gemacht, Erkennungsleistung war bei mir besser, die Timeouts sind aber zu lang.
Schade, mit Cinnamon Oberfläche (Linux Mint) gehts (noch) nicht.
Ich arbeite beruflich viel mit Transkription und Diktierfunktionen. Allerdings softwarebedingt leider meist unter Windows. Nach vielem Testen ist für mich die Wahl tatsächlich gefallen auf handy.computer. Entscheidend ist, dass man das richtige Modell für die vorliegende Hardwareumgebung aussucht und dieses richtig konfiguriert. An meinem meistgenutzten Rechner mit dedizierter Grafikkarte und 6 GB VRAM ist Wisper Turbo das Mittel der Wahl. Auf einem Mini-PC ohne dedizierter Grafikkarte funktioniert bei mir am besten Canary 1B V2. In meinen Tests ebenfalls enorm wichtig: das Voreinstellen der Sprache.
Auf meinem Mittelklasse-Handy nutze ich Whisper Plus aus dem FDroid Store. Funktioniert auch sehr gut.
Diktiert mit Handy.computer und dem Modell Whisper Turbo und voreingestellter Sprache German - kaum nachbearbeitet :-)
Dein Test ist ja erst wenige Tage alt. Merkwürdig, ich habe über einen anderen Weg heute von Speed of Sound erfahren, unter Ubuntu installiert, ebenfalls das Whisper Turbo Modell verwendet, und in einer einigermaßen ruhigen Umgebung sind meine Ergebnisse zu 99,9% perfekt. Lediglich den Satz "Eisgekühlter Bommerlunder, Bommerlunder eisgekühlt" kürzt SoS ab zu "eisgekühlt", vielleicht weil es in keinem Modell das Wort Bommerlunder kennt. Auch Deine Texte (aus Deinen Bildern) habe ich nachgesprochen, bei mir ist alles 100-prozentig richtig. Sogar Zeichensetzung, Grammatik etc. sind einwandfrei. - Ubuntu 24.04.4 LTS, 32 GB RAM, GNOME.
Hat dein System eine dedizierte Grafikeinheit? Und wenn ja, welche und mit wie viel VRAM?
Solange die Timings stimmen (und angegeben werden können?), wäre ja sogar ein schlechtes Ergebnis für Transkriptionen sehr hilfreich …