
Manchmal hat man Text-Listen, aus denen doppelte Einträge (Duplikate) entfernt werden sollen. Ein aktuelles Beispiel ist die Podcast-Sammlung der Community. Wenn viele Leute Einträge sammeln, entstehen zwangsläufig Duplikate. Aber auch in einer Tabellenkalkulation ergibt sich manchmal der Wunsch, die Doppelten zu entfernen. In diesem Artikel erläutere ich mehrere Varianten.
Als Quelle soll diese Text-Datei dienen:
Debian
Manjaro
Ubuntu
Mint
Fedora
Arch
openSUSE
Manjaro
NixOS
Fedora
ArchDort haben sich ein paar Duplikate eingeschlichen. Wenn ihr das Entfernen selbst ausprobieren möchtet, könnt ihr diese Daten als Datei dupli.txt speichern.
Im Terminal
Das Entfernen von Duplikaten auf der Kommandozeile erfolgt mit zwei Befehlen:
sort dupli.txt | uniq > new.txt
cat new.txt
Arch
Debian
Fedora
Manjaro
Mint
NixOS
openSUSE
Ubuntu
Der Befehl uniq wirkt nur bei aufeinanderfolgenden gleichen Zeilen. Daher muss die Datei zuerst sortiert werden. Wer nur die Duplikate oder die Einzigartigen ausgeben möchte, kommt mit diesen Varianten zum Ziel:
Nur die Einzigartigen: sort dupli.txt | uniq -u
Nur die Duplikate: sort dupli.txt | uniq -dFalls es wichtig ist, die ursprüngliche Reihenfolge beizubehalten, darf man keine Sortierung anwenden. Dann empfiehlt sich dieser unverständliche awk-Befehl:
awk '!v[$0]++' dupli.txt > new.txt
cat new.txt
Debian
Manjaro
Ubuntu
Mint
Fedora
Arch
openSUSE
NixOS
Falls jemand wirklich wissen möchte, was awk hier veranstaltet, bitte schön:
Dieser Befehl verwendet ein Wörterbuch (auch bekannt als Map, assoziatives Array) v, um jede Zeile und die Anzahl ihrer bisherigen Vorkommen in der Datei zu speichern.
!v[$0]++ wird für jede Zeile der Datei ausgeführt.
$0 enthält den Wert der aktuellen Zeile, die verarbeitet wird.
v[$0] prüft, wie oft die aktuelle Zeile bisher vorgekommen ist.
!v[$0] gibt true zurück, wenn v[$0] == 0 ist, oder wenn die aktuelle Zeile kein Duplikat ist. In diesem Fall wird die Zeile gedruckt (die Anweisung print wird der Einfachheit halber weggelassen).
v[$0]++ erhöht die Frequenz der aktuellen Zeile um eins.
Im Texteditor
Manche Texteditoren sind in der Lage, Duplikate zu entfernen. Als Beispiel nenne ich Gedit. Dort geht es so:

Man klickt auf: Dreipunkt-Menü → Werkzeuge → Sortieren → Duplikate entfernen → Sortieren. Wichtig ist, dass man vorher den betroffenen Text vollständig markiert. Da es sich um eine Sortierfunktion handelt, wird die Reihenfolge nicht beibehalten.
In der Tabellenkalkulation
Auch LibreOffice Calc kennt bei der Sortierfunktion das Unterdrücken von Doppelungen.
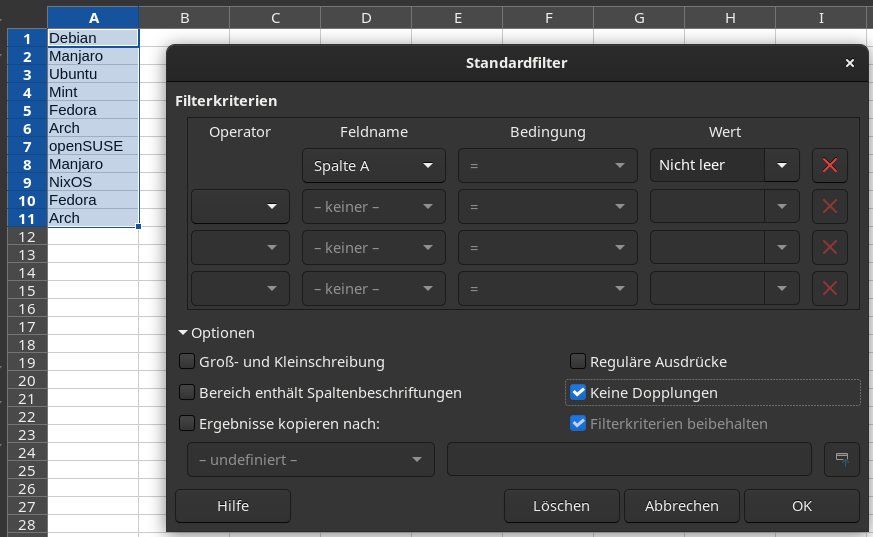
Zurerst kopieren wir die Beispieldaten in Spalte A und markieren diese Spalte. Dann wählt man im Menü aus: Daten → Weitere Filter → Standardfilter worauf dieser Dialog erscheint. Dort muss man bei Wert "Nicht leer" wählen und die Option "Keine Dopplung" einschalten. Nach einem Klick auf OK ist die Arbeit getan.
In LibreOffice Writer habe ich keine Möglichkeit gefunden, Duplikate zu entfernen. Zwar gibt es eine Sortierfunktion, die jedoch keine Option für Dopplungen hat. Das muss nicht heissen, dass es in Writer nicht doch irgendwie geht.
In der Podcast-Sammlung
Kommen wir nun zum Endgegner, dem Entfernen von doppelten Einträgen in der Podcast-Liste, die ihr so fleissig erstellt habt. Hier ist ein kleiner Auszug, damit klar ist, was ich meine:
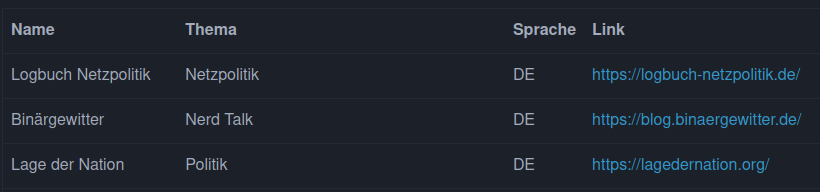
Wir haben es mit einer Markdown- und HTML-Tabelle zu tun. Für die Identifikation kommen grundsätzlich zwei Spalten infrage: Name und Link. Die Werte in diesen Spalten sind beide unscharf. Beim Name kann derselbe Podcast gemeint, doch verschieden geschrieben sein. Beim Link ist nicht klar auf die Webseite oder den RSS-Feed des Podcasts verlinkt wird. Das alles sind schlechte Voraussetzungen für das Entfernen von Duplikaten.
Zum Glück handelt es sich "nur" um ca. 150 Zeilen. Da findet man die Doppleten vermutlich durch Hinsehen. Mein Mathe-Prof sagte immer:
Integrale löst man durch scharfes Hinsehen!
Wären es 1500 Zeilen, hätte ich wohl ein Python-Programm geschrieben, um die Duplikate zu finden. Stattdessen habe ich die Tabelle (als Text, nicht als HTML) von der Webseite in LibreOffice Calc kopiert, was problemlos funktionierte:
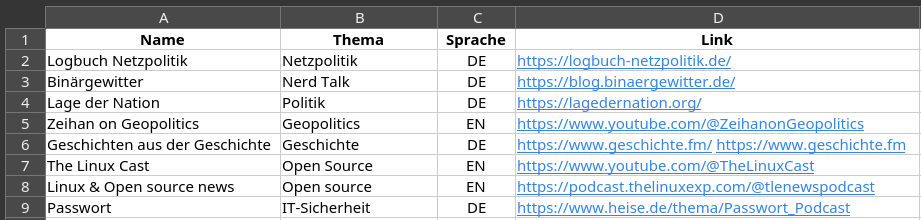
Dann habe ich nach Spalte A sortiert und beim Durchscrollen ein Duplikat entdeckt, nämlich die "Lage der Nation". Ausserdem fand ich eine Zeile ohne Link beim Podcast "In Our Time". Beides habe ich direkt im HTML des Artikels korrigiert. Dann habe ich nach Spalte D sortiert und ein weiteres Duplikat gefunden: "Holger ruft an" und "Übermedien-Podcast" haben denselben Link. Auch diese Dopplung habe ich direkt im HTML-Code entfernt.
Somit ist die Podcast-Sammlung nun bereinigt. Die Reihenfolge und die teilweise langen Themen-Beschreibungen habe ich nicht verändert. Wie sich zeigt, kommt man mit ein wenig Handarbeit manchmal schneller als Ziel als mit tollen Algorithmen.
Titelbild: https://pixabay.com/photos/rubber-stamp-wooden-stamp-duplicate-867720/
Quellen: keine



Bloß als Tüftel-Ergänzung:
shell
>
sort dupli.txt | uniq > new.txtDas uniq ist hier nicht nötig, sort bringt es schon mit:
sort -u dupli.txt > new.txtAber leider ist danach alles sortiert, wie du schon schriebst.
Weil ich mir awk-Zeugs nur schwer nicht merken kann, hätte ich es auf der shell so gemacht: `for word in $(cat dupli.txt); do if ! grep $word
Na da hat es meinen Beitrag schön zerbröselt. In der Voransicht hat alles gepasst.
Checkt das niemand mehr vor der Veröffentlichung?
Doch, aber ich weiss nicht, wie man das nachträglich korrigieren kann. Gemeint ist:
sort -u dupli.txt > new.txtMeh
:-)
Und vieles mehr, das unterging.
Naja. So wichtig bin ich jetzt auch nicht.
Der neue Editor scheint echt gut zu sein. 😊
uniq kann übrigens auch angewiesen werden, nur eine bestimmte Anzahl Zeichen oder Felder/Spalten z.B. bei CSV Dateien zu prüfen:
https://www.man7.org/linux/man-pages/man1/uniq.1.html
Es geht dort mit "Tools->Scripts->Editing->Remove Duplicate Lines" auf die zuvor markierten Zeilen anwenden.
Die Anleitung für gedit lieferte den Einstieg (ebenfalls Tools) .