Manchmal ist es nötig, einen Text aus einem Bild zu extrahieren, zum Beispiel weil in einem PDF-Dokument ein Text als Foto hinterlegt wurde, oder um einen beliebigen Schriftzug aus einem Bild in bearbeitbaren Text umzuwandeln. Dafür gibt es viele Werkzeuge, die mittels OCR (optical character recognition) den Text im Bild zu einem richtigen Text konvertieren. Wer es ganz einfach und benutzerfreundlich mag, wird am Werkzeug TextSnatcher Gefallen finden.
Die Benutzeroberfläche dieser Anwendung könnte nicht einfacher sein: Man klickt auf die Schaltfläche 'Snatch Now', worauf sich das Standard-Screenshot-Werkzeug der Desktop-Umgebung öffnet. Es empfiehlt sich, einen Teil-Screenshot zu erstellen, der nur den gewünschten Text enthält. Sobald der Screenshot erstellt wurde, läuft im Hintergrund die Tesseract-Engine los, und versucht den Text zu erkennen. Je hochauflösender und klarer der Text im Bild ist, desto besser wird das Ergebnis. Die Texterkennung geht sehr schnell vonstatten und das Ergebnis wird von TextSnatcher in die Zwischenablage kopiert.
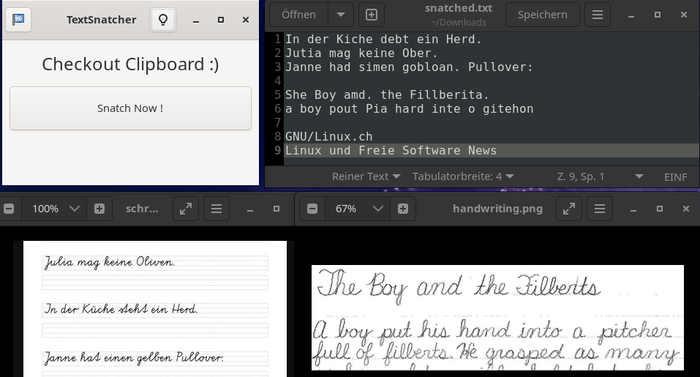
In meinem Beispiel (siehe Screenshot) sind die Bedingungen alles andere als optimal. Die deutsche Handschrift hat eine sehr geringe Auflösung; ausserdem wird Deutsch von TextSnatcher noch nicht unterstützt. Im Texteditor sieht man das Ergebnis. Auch mit der englischen Handschrift hat das Werkzeug seine Mühe. Fehlerfrei gelang die Konvertierung des GNU/Linux.ch-Logos inklusive des Untertitels. Aktuell unterstützt TextSnatcher die Sprachen: Englisch, Chinesisch, Tamil, Japanisch, Französisch, Spanisch und Arabisch.
TextSnatcher steht als Flatpak für die Installation zur Verfügung.


