
Hinweis der Redaktion: Diesen Beitrag habt ihr euch in den Artikelvorschlägen gewünscht.
KI-Tools sind überall – Texte generieren, Bilder erstellen, Videos bearbeiten. Viele greifen dabei sofort zu den großen Namen: Google Gemini, OpenAI ChatGPT, Perplexity oder Grok. Sie sind bequem, leistungsfähig und immer erreichbar. Der Preis dafür: Diese Dienste sind nicht Open Source und arbeiten mit den Daten, die Nutzer:innen eingeben – inklusive sensibler Inhalte wie Referenzfotos für Bildbearbeitung. Wer solche Funktionen nutzt, übergibt seine Kreativität und Privatsphäre an Firmenserver.
Self-host statt Cloud-KI
Immer mehr Projekte ermöglichen es, KI selbst zu betreiben – auf dem eigenen Rechner, ohne dass Daten nach außen wandern. Das ist nicht nur gut für die Privatsphäre, sondern bewahrt auch vor Hersteller-Lock-in.
- Texte lokal mit Ollama: Ollama lädt und startet Sprachmodelle wie LLaMA, Mistral oder Phi-3 direkt auf dem eigenen System. Für Text reicht häufig schon ein gut ausgestatteter Laptop – die Modelle sind vergleichsweise ressourcenschonend.
- Bilder lokal mit Stable Diffusion: Stable Diffusion erzeugt Bilder auf Basis von Textprompts. Komfortabel wird es mit Oberflächen wie Automatic1111 oder ComfyUI. Für flüssige Arbeit ist jedoch eine leistungsfähige GPU nötig; ohne GPU laufen Jobs deutlich langsamer.
Zwischen Bequemlichkeit und Freiheit
Proprietäre Smartphone-Apps sind oft ein Knopfdruck-Erlebnis: GIF fertig, Zeitlupe exportiert, Musik darunter – erledigt. Aber man erkauft sich diese Bequemlichkeit durch Abhängigkeit und Datenabgabe. Gerätewechsel, Abo-Modelle oder Funktionsänderungen liegen nicht in eurer Hand.
Self-hosted KI bedeutet das Gegenteil: volle Datenhoheit, freie Wahl der Werkzeuge, transparente Entwicklung und Community-Wissen. Wer eine geeignete Grafikkarte besitzt, erhält Bild-KI in Studioqualität – ohne je ein Foto an Google, OpenAI, Perplexity oder X.ai zu schicken. Für Text-KI ist der Einstieg noch leichter: Modelle lassen sich testen, austauschen und offline nutzen.
Praktischer Einstieg (kurz & knapp)
- Texte: Ollama installieren, ein passendes Modell ziehen (
ollama run mistralo.ä.), lokal chatten – ohne Cloud. - Bilder: Stable Diffusion + Automatic1111 oder ComfyUI einrichten; ideal sind GPUs mit ausreichend VRAM. Ohne GPU klappt es auch, aber langsamer.
- Workflows: Eigene Presets bauen (z.B. „GIF aus Bildsequenz“, „Zeitlupen-Interpolation“, „Stil-Transfer“) und nach Bedarf erweitern.
- Privatsphäre: Medien bleiben auf dem eigenen Rechner – keine unfreiwillige Trainingsbeute, kein Tracking, keine Abo-Fallen.
Ollama und Nextcloud Assistent
Ein Beispiel ist der Nextcloud Assistent mit wahlweise Ollama, der Mistral API, oder der ChatGPT API. Aus Datenschutzgründen würde ich entweder Mistral API empfehlen, oder Ollama. Wobei Mistral performanter ist als eine KI auf demselben Rechner/Server ohne richtige GPU.
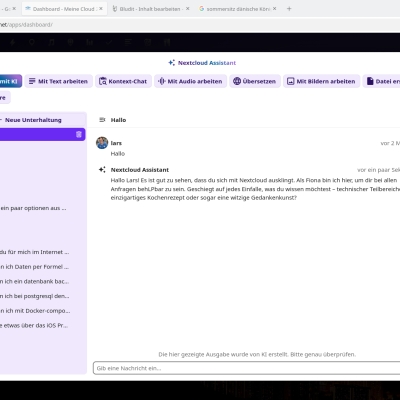
Mistral als DSGVO-konforme Alternative
Eine gute Alternative zu Selfhosted wäre Mistral, hier nutzt man zwar einen kommerziellen Dienst, aber dies ist datenschutzfreundlicher.
Fazit
Die Frage ist nicht nur, was bequemer ist, sondern wem eure Kreativität gehört. Self-host AI gibt euch die Werkzeuge in die Hand – frei, lokal und kontrollierbar. Wer sich von proprietären Galerie-Apps oder Cloud-Assistenten locken lässt, bekommt Komfort; wer selbst hostet, behält die Souveränität.



Der Artikel unterschlägt etwas die imensen Hardware-Anforderungen, die eines dieser „KI“-Systeme hat 😉 Ohne eine Nvidia-GPU mit mindestens 12 GB VRAM muss man nach meiner Erfahrung nicht einmal unter Linux anfangen. Wer will schon minutenlang auf eine Antwort warten?
So immens sind diese Anforderungen nicht. Eine Geforce GTX 1050 Ti mit 6gb war brauchbar für kleine Ollama Modelle. Meine jetzige RTX 3070 mit 8gb ist ebenfalls gut genug für kleine Anwendungen. Gebrauchte RTX 3060 mit 12gb sind momentan günstig zu haben.
Für Ollama ist übrigens diese Web-UI empfehlenswert: https://github.com/open-webui/open-webui
Oder eben die Webui die ich im Beitrag erwähnt hatte.
Mag sein, dass es sinnvolle Einsatzszenarien für die kleinen Modelle gibt, die Ergebnisse für einfache und allgemeine Fragen/Aufgaben waren bei mir aber so schlecht, dass ich sie guten Gewissens als unbrauchbar für den generischen Einsatz bezeichnen kann. Man braucht „KI“ im Regelfall einfach sehr potente Hardware und die kostet, auch oder gerade im Betrieb und das sind „KI“-Modelle bei ihren Fehlerquoten nicht wert IMHO.
Das ist der Nachteil, das lange warten. Aber auch meinem Beelink Rechner daheim habe ich eine KI auch zum laufen bekommen für die Vision Modelle aber es dauert ewig.
In unserem Haus gibt es keine starken Rechner mit Grafikkarten. Ich überlege ob ich, wenn ich demnächst ein Nas baue es direkt so auszustatten das man da auch KI drauf laufen lassen könnte. Aber was da tatsächlich gebraucht wird finde ich schwer einzuschätzen
Das wird bestimmt eine nvidia RTX 3060 oder vergleichbares siehe Kommentar weiter oben. Die sache ist auch wie teuer wird sowas wegen dem Stromverbrauch. Sollte man nicht vergessen.
Eigentlich sollten für kleinere und mittlere KI-Modelle (reine Chat LLMs) die integrierten NPUs (Neural Processing Units), die Bestandteil moderner CPUs wie AMD Ryzen AI oder Intel Lunar Lake sind vollkommen ausreichend sein, ohne dass die Antwortzeiten mehrere Minuten dauern müssen. Je mehr TOPS (Tera Operations per Second) eine NPU hat, desto besser. Ob und wie bei lokalen KI-Anwendungen eine NPU mit einer leistungsstarken GPU genau zusammenarbeitet, also wer dann welche Aufgaben übernimmt, habe ich noch nicht verstanden. Vielleicht wandert zukünftig noch mehr Funktionalität von den GPUs in diese NPUs?
DAs ist schön, nur wie wird die modelle installiert, was soll man beachten und warum nicht als Gui LM Stuidio nutzen ?
Seit ich die 9060XT 16GB besitze, zeigt mir AMD in der Treibersoftware Werbung für Amuse AI (GUI für lokale Bild- und Video-KI-Modelle) und AMD Chat (lokales ChatGPT) an. Extrem einfach einzurichten und zu nutzen. Dreamshaper Lightning XL (AMDGPU) leistet echt gute Arbeit, wenn man ein paar Avatare für Chats oder Foren erstellen will.
Ich hätte mehr sowas wie eine Anleitung erwartet. Beim mistral beispiel braucht es das nicht umbedingt, weil es die im verlinkten Artikel gibt. Aber Stable Diffusion sorgt nur für Stirnrunzeln. Das wäre aber wass ich möchte.