
Trotz Sommerloch und einem bisher artikelfreien Dienstag, kommt mir zu später Stunde doch noch eine Idee. Eigentlich wollte ich darüber schreiben, dass die e-Foundation (/e/OS, Murena, Gaël Duval) es nach Jahren nicht geschafft hat, alle Apps deinstallierbar zu machen. Vielleicht erinnert ihr euch an diesen Artikel und an die Antwort darauf. Seit zwei Jahren ist nichts geschehen und eine Vielzahl von /e/OS-Apps kann nach wie vor nicht deinstalliert werden.
Bei der Suche nach der Antwort habe ich Foren durchstöbert, die normale Internetsuche verwendet und Perplexity befragt. In deren KI-Antwort habe ich keine Fehler gefunden, aber Links entdeckt. Die Antwort enthält ca. 10 Quellenverweise, die nicht halluziniert sind:
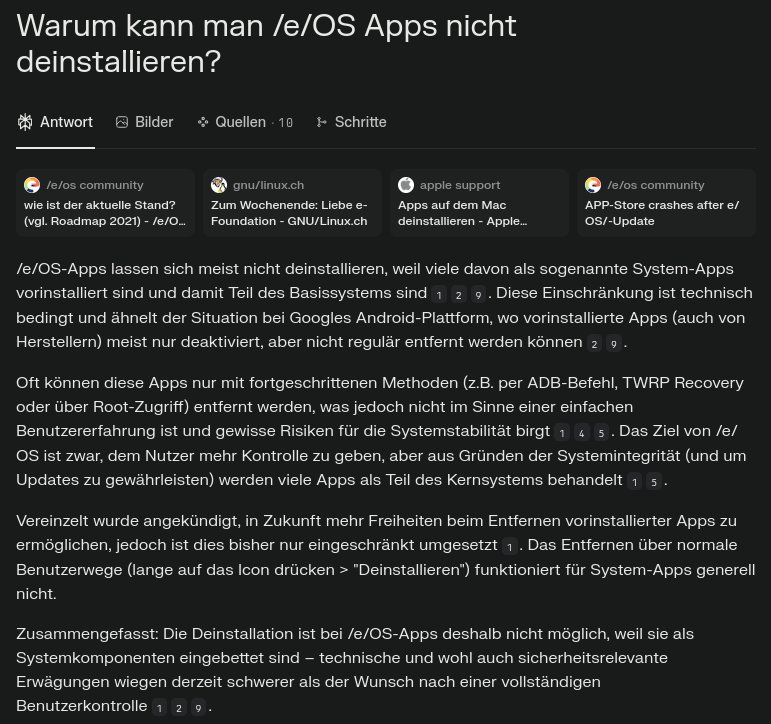
Klickt man (oben) auf die insgesamt 18 Quellen, sieht man das:
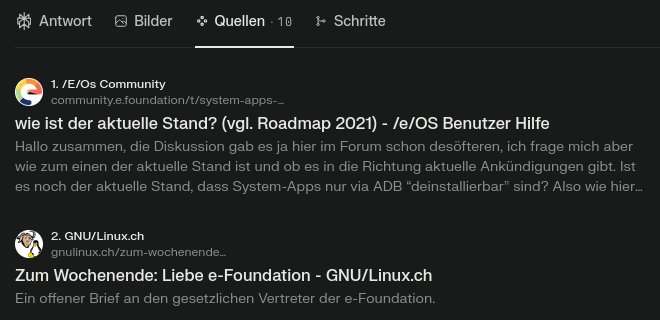
In der Quellen-Liste finden sich mehrere Einträge, die auf meine Artikel bei GNU/Linux.ch verweisen. Das wundert mich nicht, da ich bei Websuchen häufig auf Beiträge stosse, die von unserer Community geschrieben wurden. Dabei kam mir ein Blog-Post von Cloudflare in den Sinn, der gestern erschien:
Cloudflare berichtet, dass die KI-gestützte Suchmaschine Perplexity auf Inhalte von Websites zugreifen soll, obwohl diese Crawler explizit blockiert haben. Die Erkenntnisse deuten darauf hin, dass das Unternehmen möglicherweise etablierte Web-Crawling-Restriktionen umgeht, die über Jahrzehnte ein ungeschriebenes Gesetz waren.
Beurteilung
Wie zuvor erwähnt, findet man seit Anbeginn des GNU/Linux.ch-Projektes unsere Beiträge häufig in den normalen Websuche-Ergebnissen. Dagegen ist grundsätzlich nichts einzuwenden; unsere Inhalte stehen unter der CC-BY-SA-Lizenz, womit wir die Weiterverbreitung ausdrücklich unterstützen, sofern die BY-Bedingung eingehalten wird. Unsere Redaktion und die vielen freien Autoren schreiben nicht, weil sie Geheimnisse bewahren wollen, sondern weil sie Wissen vermitteln möchten. Dieses Wissen erstellen wir in unserer Freizeit, sei es als Hobby, aus Interesse an der Sache, oder aus altruistischen Beweggründen. Viele sehen in ihrer Tätigkeit auch einen ungefragten Bildungsauftrag.
Soweit, so gut. Doch was ist mit dem BY in der CC-Lizenz? Damit ist die Pflicht zur Namensnennung gemeint. In unserem Impressum (und bei Über uns sowie bei Mitschreiben) steht unter dem Kapitel Nachweise:
Die von uns auf GNU/Linux.ch veröffentlichten Artikel stehen, sofern nicht anders angegeben, unter der CC-BY-SA 4.0 Lizenz. Die Namensnennung (BY) muss in der Form: GNU/Linux.ch - Autorennamen erfolgen, sofern der Autorenname im jeweiligen Artikel angegeben ist. Andernfalls reicht die Nennung unserer Plattform GNU/Linux.ch.
Dieser lizenzrechtlichen Verpflichtung folgt Perplexity (und alle anderen KI-Search/Chat-Bots) nicht. Wenn es um Links auf unsere Artikel geht, ist das nicht notwendig. Doch die LLMs (KI-Modelle) aggregieren unsere Inhalte, um daraus ein eigenes Produkt zu schaffen, nämlich die KI-Antwort (siehe erstes Bild). Ich wünsche mir, dass die KI-Bots den jeweiligen Lizenzbedingungen entsprechen. In den Reitern (siehe Bild 2) wäre noch genug Platz, um dem zu entsprechen. Sie könnten neben dem Link auch die Autor:in nennen, um die Pflicht der Namensnennung zu erfüllen.
Als Witz (es ist traurig, das zu sagen) werde ich bei Perplexity (The Cube, Monahan Road, Cork, T12 H1XY, Republic of Ireland) einmal nachfragen, ob und wie sie unsere Schreibleistung vergüten möchten. Ich sage euch Bescheid, falls ihr demnächst Millionäre werdet.
Titelbild: https://pixabay.com/photos/justice-statue-lady-justice-2060093/ (bearbeitet)
Quellen:
https://www.perplexity.ai/search/warum-kann-man-e-os-apps-nicht-NO9fe4V_QYKhTP8kHmI0RQ?0=d



Anubis davor schalten. Muss ich auch noch machen, bin nur zu faul mein NGINX Konstrukt auf SOCKET zu migrieren. Und auch noch keine Idee wie.
https://github.com/TecharoHQ/anubis
Invidious Nadeko hat früher anubis benutzt, ist dann aber auf go-away umgestiegen. Das müsste es sein: https://github.com/WeebDataHoarder/go-away
Ich bin immer auf der Suche nach guten Tools.
Gibt es eine pro/con übersicht? Anubis hat die größte Entwickler-Basis derzeit usw.
Warum sollte ich go-away nutzen?
Das klingt vielversprehend! Ich habe mir die Dokumentation auf der Seite durchgelesen und wurde zugegebenermaßen nicht wirklich schlau.
Weiß jemand von Euch, ob ich Anubis oder eine Alternativlösung uch auf einem Hosted Webspace wie z.B. IONOS, Strato etc. betreiben kann?
Ich habe noch ein privates Foto-Blog nebebei, das ich nicht selbst hoste, sondern das bei einem Webhoster liegt (IONOS). Dort habe ich nur Zugriff auf den Webspace, kann aber kein Docker oder ähnliches nachinstallieren oder den Apache konfigurieren, würde ich so eine Lösung implementieren wollen. Bis jetzt habe ich über die robots.txt unliebsame Crawler ausgesperrt. Wenn die KI allerdings auf die robots.txt pfeift, brauche ich was stärkeres. 😁
Aktuell ist mir kein Tool bekannt, dass derartiges ohne Zugriff auf NGINX,Apache und/oder docker kann.
Anubis u.Ä. benötigen eine tiefe System-Integration.
Hat die KI nicht eine eigene Antwort erstellt indem sie mehrere Quellen zusammengefaßt hat?
Das geht noch weiter, Perplexity ignoriert nicht nur die Robots.txt, sondern ändert auch den User-Agent und nutzt Ips außerhalb des bekannten Perplexity-Ips.
"Perplexity umgeht gezielt Sperren und greift geschützte Inhalte ab" https://www.derstandard.at/story/3000000282286/perplexity-umgeht-gezielt-sperren-und-greift-geschuetzte-inhalte-ab
Am ende brauchen wir die eID um Menschen von KI zu unterscheiden 😒