
Der Titel klingt nach einer einfachen Aufgabe. Allerdings geht es um einen Vergleich von Verzeichnissen, die unterschiedlich strukturiert sind. Hintergrund der Sache ist eine Bereinigung der Bild-Ordner auf der GNU/Linux.ch-Nextcloud. Dort gibt es zwei Verzeichnisse mit Bildern (Logos, Banner, Werbung, usw.). Die Inhalte der Ordner sind ähnlich, aber nicht gleich. Ausserdem gibt es in einem Verzeichnis Unterverzeichnisse, im anderen nicht. Nun gilt es, herauszufinden, welche Unterschiede bei den Dateien bestehen.
Auf der Suche nach der optimalen Lösung bin ich in der Mitte angekommen. Vermutlich gibt es elegantere und/oder einfachere Lösungen. Zuerst habe ich darauf gehofft, dass Meld diese Aufgabe meistern kann; kann es nicht.
Dann kam mir folgende Idee: Ich erstelle eine Dateiliste für jedes der beiden Verzeichnisse, und zwar ohne die Struktur der Unterverzeichnisse. Dann diffe ich die beiden Dateien.
So sehen die beiden Verzeichnisse aus (mit Fake-Dateien):
Verzeichnis 1:
├── a.txt├── subA│ ├── subAtext2.txt│ └── subAtext.txt├── subB│ ├── subBtext2.txt│ └── subBtext.txt├── text.txt└── wrt.txt
Verzeichnis 2:
├── b.txt├── subAtext2.txt├── subAtext.txt├── subBtext.txt└── text.txt
Wie ihr seht, gibt es ein paar Unterschiede bei den Dateien, unabhängig von der Verzeichnisstruktur. Um die Verzeichnisse zu vergleichen, habe ich dieses Kommando in jedem Verzeichnis ausgeführt:
find -type f -execdir basename {} .po ';' | sort > a.txt
Zuerst habe ich es mit diesem Kommando versucht:
ls -R -1 .In der Ausgabe sind jedoch die Verzeichnisse und Leerzeilen enthalten, weshalb ich es verworfen habe.
Das find-Kommando sucht nur nach Dateien (ohne Verzeichnisse) und entfernt die Pfad-Angabe. Ausserdem wird das Ergebnis sortiert und in eine Textdatei geschrieben, die später für den Vergleich gebraucht wird. Der Inhalt der Datei a.txt (für das Verzeichnis mit Unterverzeichnissen) sieht so aus:
a.txtsubAtext2.txtsubAtext.txtsubBtext2.txtsubBtext.txttext.txtwrt.txt
… und b.txt für das flache Verzeichnis:
b.txtredaktion.jpg.xmlsubAtext2.txtsubAtext.txtsubBtext.txttext.txt
Jetzt kommt der einfache Teil. Mit dem sdiff Kommando sieht man sofort, welche Dateien fehlen oder mehr sind:
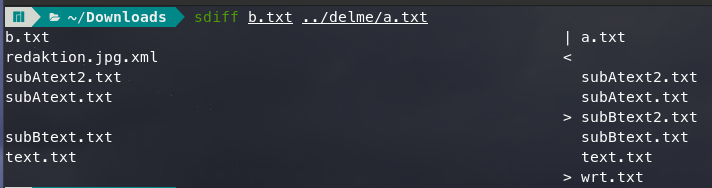
Ich bin mir sicher, dass das nicht die beste Lösung ist. Zwar funktioniert sie, es sind jedoch drei Schritte notwendig, um zum Ergebnis zu kommen. Ihr findet bestimmt eine Einschritt-Variante. Schreibt sie in die Kommentare.
Nachtrag
Im Kommentar von Jens ist der wichtige Teil verloren gegangen, weshalb ich ihn hier nachhole:
Eigentlich sind es immer noch drei Schritte, aber nun in einem Einzeiler zusammengefasst. basename braucht man nicht, denn das kann find selbst. Funktioniert in der bash, zsh habe ich nicht getestet:
sdiff <(find dir1/ -type f -printf '%f\n' | sort) <(find dir2/ -type f -printf '%f\n' | sort)Danke, Jens.



Eigentlich sind es immer noch drei Schritte, aber nun in einem Einzeiler zusammengefasst. basename braucht man nicht, denn das kann find selbst. Funktioniert in der bash, zsh habe ich nicht getestet:
sdiff
Den Goldstandard zum Verzeichnisse vergleichen und synchronisieren hat der Total Commander gesetzt.
Meld ist für reine Dateivergleiche eine gute Alternative. Aber für Abgleich von Verzeichnissen mitsamt enthaltenen Dateien nach Inhalt oder Datum habe ich noch nichts Gescheites gefunden.
Eine VIM Lösung: DirDiff.vim https://www.vim.org/scripts/script.php?script_id=102
Sind zwar auch mehrere Schritte: Ich wechsele zuerst immer in die Verzeichnisse die ich vergleichen will, damit ich mit einem relativen Pfad arbeiten kann: find . -not -path './.*' | sort > /pfad/zur/ausgabedatei.txt
Dann mit comm vergleichen comm -2 -3 Datei1 Datei2 > Ergebnis
Option Wirkung -1 unterdrückt einzigartige Zeilen aus DATEI1 -2 unterdrückt einzigartige Zeilen aus DATEI2 -3 unterdrückt gleiche Zeilen beider Dateien
....nur noch zwei Befehle als Einzeiler.
$ diff -rq test1 test2 | sort Nur in test1: a.txt. Nur in test1: subA. Nur in test1: subB. Nur in test1: wrt.txt. Nur in test2: b.txt. Nur in test2: subAtext2.txt. Nur in test2: subAtext.txt. Nur in test2: subBtext.txt.
Es hängst stark von der Fragestellung an die Daten ab. Vielleicht folgendes als ersten Startpunkt:
find verzeichnis_a -type f -print0 | xargs -0 sha256sum >tree_data.a find verzeichnis_b -type f -print0 | xargs -0 sha256sum >tree_data.b
Das Nullargument bei find und xargs hauptsächlich falls Whitespace oder sonstiger Schrott in den Dateinamen vorkommt. Man könnte jetzt die erstellten Daten anschauen:
cat tree_data.a tree_data.b | sort | less
oder eine pretty print variante davon, die Leerzeilen einfügt wenn sich der Key,d.h. die Checksumme, zur vorhergehenden Zeile unterscheidet einfügt:
cat tree_data.a tree_data.b |sort |awk 'BEGIN{getline; key=$1; print $0}//{if($1 != key){key = $1; print ""; print $0}else{print $0}}' |less