
Wie jeder Beitrag zum Wochenende ist das ein Meinungsartikel.
Mit dem Titel dieses Wochenendartikels bin ich nicht zufrieden, weil ich zwei Themen im Kopf habe: "Ist das Training von Large Language Models eine Urheberrechtsverletzung?" und "Wann läuft sich die KI tot?". Ihr werdet beim Lesen dieses Beitrags erleben, in welche Richtung sich meine Schreiberei entwickelt. Zumindest taugt die zweite Idee für ein besseres Titelbild als das Thema "Urheberrechtsverletzung".
Beginnen möchte ich mit dem langweiligeren und schwierigerem Aspekt der Urheberrechtsverletzung. Vielleicht habt ihr gelesen, dass sich der Zeitungsverlag der New York Times mit dem Hauptakteur im KI-Geschäft, der von Microsoft finanzierten Firma OpenAI, eine heftige Schlacht liefert. Beim "Totlaufen" geht es um den inzestuösen Charakter von Large Language Models (LLM). Ich hätte mit dem Schreiben nicht begonnen, würde ich nicht einen Zusammenhang zwischen den beiden Sichtweisen sehen.
So, genug der Vorrede; jetzt geht es los mit der Wochenendlektüre:
Urheberrecht
Seit einiger Zeit klagen Rechteinhaber (Verlage, Autoren, Musiklabels, Kunstschaffende ...) gegen die Betreiber der grossen KI-Modelle (nennen wir sie Large Content Models - LCMs, weil es nicht nur um Texte, sondern um alle Medienformate geht). Sie argumentieren, dass die LCMs ihre (urheberrechtlich geschützten Inhalte) verwenden, um die KI-Modelle zu trainieren. Aus diesen Modellen werden (kostenpflichtige) Services gebaut, die die Originalinhalte potenziell ersetzten/imitieren/nachahmen oder ihnen gleichen.
Beispiel:
- Input: "Erstelle mir einen Song im Stil von Abbas Mama Mia."
- Verarbeitung: Statistische Auswertung auf der Grundlage aller verfügbaren Informationen (das Internet) für diesen Abba Song.
- Output: Ein "neuer" Song, der dem Original sehr ähnlich ist.
Da wir bei GNU/Linux.ch schon viele Beiträge zur Funktionsweise von Künstlichen Neuronalen Netzwerken (KNN) geschrieben haben, erspare ich euch eine Wiederholung. Deshalb gibt es hier nur eine kurze Zusammenfassung (die Wissenschaftler unter euch mögen mir verzeihen).
Wenn man mit einem KNN eine Eingabe (z. B. das Bild einer Katze) in eine Ausgabe (das Wort "Katze") umwandeln möchte, nehme man eine Matrix von numerischen Werten, die untereinander schichtenweise verbunden sind (die Werte von Schicht Eins mit allen Werten von Schicht Zwei, usw.). Auf allen Verbindungen sitzen Schwellwerte, die darüber bestimmen, ob die verbundene Zelle aktiviert wird oder nicht. Am Ausgang dieser Matrix erhält man (zu Beginn) ein zufälliges Ergebnis. Nun wird es interessant. Das Ergebnis wird mit dem gewünschten Ergebnis verglichen und der Unterschied berechnet. Dieser Unterschied wird rückwärts durch die Matrix geschickt, um die Schwellwerte leicht anzupassen. Dieses Hin und Her (Training) wiederholt man so lange, bis das Ergebnis dem gewünschten Ergebnis (annähernd) entspricht (das Wort "Katze"). Das Problem ist, dass es zwischen der Eingabe und er Ausgabe keinen funktionalen, sondern nur einen statistischen Zusammenhang gibt. Das unterscheidet KNN wesentlich von klassischen Algorithmen, die überprüfbar und vorhersagbar sind. KNNs sind weder überprüfbar noch vorhersagbar; es sind Wahrscheinlichkeitswerte.
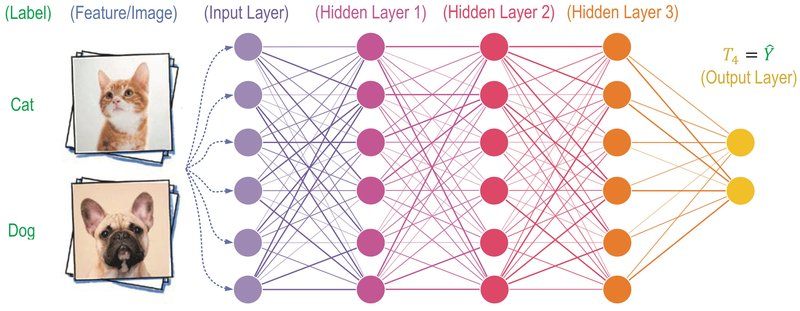
Was bedeutet das für einen Satz, den ihr in ChatGPT eintippt? Die Wörter eures Satzes werden in ein KNN gekippt. Das KNN ermittelt die statistisch wahrscheinlichsten Wörter, um eine Antwort auf euren Satz zu liefern. Die Ausgabe ist nicht vorhersagbar und hängt von der Architektur des KNN, und von den Trainingsdaten ab. Wie gut das funktioniert, habt ihr alle bereits ausprobiert.
Da die grossen KI-Firmen, alle verfügbaren Quellen für das Training ihrer Modelle (KNN) verwenden, sind auch die Texte der New York Times (NYT) dabei. Der Verlag erwägt nun nach langen Verhandlungen mit der Firma OpenAI, eine Urheberrechtsklage einzureichen. Falls diese zustande kommen sollte, könnte es für OpenAI schlecht aussehen. Der Zeitungsverlag befürchtet, dass die KI-Ergebnisse (die von OpenAI auf der Grundlage der NYT-Artikel generiert werden), das Kaufen und Lesen der Zeitung überflüssig machen, weil der KI-Einbau von Microsoft in alle ihrer Produkte, einen einfacheren Zugang für die Kunden bieten (Bing, Office, 365, Teams). Falls die NYT sich nicht aussergerichtlich mit OpenAI einigen kann, wird es wohl zur Klage kommen, die für OpenAI (Microsoft) übel ausgehen könnte. Wenn die Richter:innen der NYT recht geben, wird die Schadenssumme wohl astronomisch hoch sein.
Gemäss der Quelle könnten 150.000 US-Dollar pro "absichtlicher" einzelner Rechtsverletzung möglich sein. Multipliziert man das mit den Millionen von Trainingsdaten, die OpenAI von der NYT bezogen hat, kommt man auf eine sehr hohe Strafe, die vermutlich das Ende der Firma OpenAI bedeuten würde. Dabei reden wir nur von den Schadensersatzansprüchen eines einzigen Verlages.
Aber dazu wird es nicht kommen. Die USA sind nicht dafür bekannt, dass sie technologische Entwicklung, wirtschaftliche Vorherrschaft und üppige Steuereinnahmen durch radikale Gerichtsurteile abwürgen. Interessant finde ich, dass sich die Rechtsprechung noch im "Neuland" befindet; Präzedenz-Urteile stehen noch aus.
Ich selbst habe grosse Mühe, mir eine Meinung zu dieser Rechtsfrage zu bilden. Als Wirtschaftsinformatiker bin ich kein Jurist, weshalb ich kein Wissen zum Urheberrecht in dieser Angelegenheit habe. Meine Grundeinstellung ist eher ablehnend. Alle Erfahrungen, die ich bisher mit ChatGPT und Konsorten gesammelt habe, verheissen nichts Gutes. Der Artikel wird zu lang, falls ich meine Bedenken alle aufzählen würde. Ihr ahnt, worum es geht: Bias in den Trainingsdaten, Verlust der eigenen geistigen Leistung, Nichtberücksichtigung von marginalisieren Gruppen, Fake-of-everything, False-positives, Überforderung des Bildungswesens usw.
Gemäss europäischer Rechtsprechung würden die laufenden Klagen abgelehnt. Wenn es um die urheberrechtliche Bewertung der Trainingsdaten geht, sind Vervielfältigungen von rechtmässig zugänglichen Werken für das Text- und Data-Mining auch ohne Einwilligung des jeweiligen Urhebers zulässig. Ausser, der Rechteinhaber hat explizit sein Opt-out für das Mining erklärt. Beim generierten Output sieht es so aus, dass Computerprogramme wie ChatGPT grundsätzlich keine persönliche Schöpfung erbringen und somit nicht als Urheber betrachtet werden. Vielleicht erinnert ihr euch an das Selfie vom Affen Naruto, dem keine Urheberschaft zugesprochen wurde. Der dritte Aspekt beim Urheberrecht betrifft die Frage, ob KI-Anwender:innen ein Recht an den von ihnen erzeugten KI-Ergebnissen haben. Das hängt vom "Abstand" ab. Juristisch liest sich das so:
Für eine zulässige freie Benutzung müssen angesichts der Eigenart des neu geschaffenen Werks die entlehnten eigenpersönlichen Züge des geschützten älteren Werks verblassen.
Es kommt auf den Einzelfall an. Falls die Wertschöpfung und der inhaltliche Abstand gross genug sind, dürft ihr ein von einer KI generiertes Ergebnis (auf der Grundlage eures Prompts) als das eure bezeichnen.
Hamsterrad
Die Erklärung der Hamsterrad-These ist einfach: LCMs werden mit den Inhalten des Internets und den von euch eingesammelten Cloud-Daten trainiert. Aus diesem Fundus werden die Ergebnisse generiert. Diese Ergebnisse sind wiederum der Input für die nächste Trainingsrunde der LCMs. Je mehr ihr KI-Dienste als Ersatz für eigene geistige Leistung einsetzt, desto grösser wird der per KI erzeugte Inhalt. Mengenmässig werdet ihr nicht dagegen ankommen; die KI-Inhalte sind euch quantitativ überlegen.
Aktuell gibt es 8.1 Mrd. Menschen auf der Erde. Davon haben 5.4 Mrd. Personen einen Internet-Zugang und dienen als Futter für die LCMs. Davon werden aber nur die westlichen Sprachen berücksichtigt, weshalb die Modelle nur von ca. 1.5 Mrd. Beitragenden gefüttert werden, was ca. 20 % ausmacht. Diese Zahlen sind ohne Gewähr. Dieses Verhältnis führt zu einer Unterrepräsentation von Menschen mit nicht westlichen Sprachen, die man überwiegend im Globalen Süden und im Osten findet. Die geschätzte Zahl von 1.5 Mrd. menschlichen Inhaltslieferanten ist auch falsch, weil nur ein Bruchteil davon originäre Inhalte produziert. Ich nehme an, dass es 99 % Konsumenten und 1 % Produzenten gibt. Damit reduziert sich der Input für die LCMs auf 15 Millionen, womit die von Menschen erzeugten Eingaben auf ein lächerliches geringes Mass sinken.
Anfragen an die KI sind im Trend. Immer mehr Anwender:innen verwenden sie für die Suche im Internet (als Ersatz für die klassische Internetsuche), als Hausaufgaben-Löser, für die Zusammenfassung von Zeitungsartikeln, für automatische Antworten auf E-Mails, zum Generieren von Musik nach eigenem Geschmack und für perfekte Bewerbungsfotos. Im Grunde gibt es keinen Internet-gestützten Lebensbereich, der sich nicht durch den Einsatz von KI einfacher (weniger wertschöpfend) gestalten lässt.
Schaut man auf die Medienkompetenz in der Bevölkerung und vergleicht diese mit dem Hang zum Komfort um jeden Preis, kombiniert mit der Willigkeit, Neuerungen unreflektiert anzunehmen, wird das Hamsterrad noch lange mit echten Inhalten bedient, bis es irgendwann zu einem Kipppunkt kommt. Dieser Punkt ist erreicht, wenn die Modelle nur noch, oder überwiegend mit ihrem eigenen Output trainiert werden. Ich schätze, dass dieser Punkt in 5 bis 10 Jahren erreicht wird. Das genügt, um die Nutzer von der Droge KI-Unterstützung abhängig zu machen.
Ab diesem Zeitpunkt befinden sich die LCMs vollständig im Hamsterrad; sie beziehen ihre Lerninhalte nur noch aus sich selbst. Was dann passiert, ist schwer einzuschätzen. Meine Hypothese ist, dass sich die Antworten (Texte, Bilder, Videos) der KIs auf eine Singularität hinbewegen. Zum Schluss werden alle Prompt zum gleichen Ergebnis führen, oder ein unsinniger Random-Wert sein. Wenn wir Glück haben, wird jede ChatGPT-Anfrage mit '42' beantwortet.
Titelbild: https://pixabay.com/photos/hamster-wheel-pocket-pets-pet-10126776/
Quellen:
https://law.ch/lawnews/2023/02/chatgpt-urheberrecht-wem-gehoert-der-output/
https://countrymeters.info/de/World
https://de.statista.com/statistik/daten/studie/805920/umfrage/anzahl-der-internetnutzer-weltweit/
https://www.heise.de/news/Affen-Selfie-Affe-Naruto-bekommt-keine-Copyright-Tantiemen-4030277.html



"Ich schätze, dass dieser Punkt in 5 bis 10 Jahren erreicht wird. Das genügt, um die Nutzer von der Droge KI-Unterstützung abhängig zu machen."
Ich denke das geht schneller. Guckt euch nur die Smartfonzombies in der realen Welt an.
Handy am Steuer: Die tödliche Gefahr (von 2018)
SWR Marktcheck
Jeder zehnte Verkehrstote geht laut Schätzungen inzwischen auf das Konto einer Handynutzung am Steuer. Doch Einsicht zeigen ertappte Handy-Sünder nur selten.
https://www.youtube.com/watch?v=AmwNm_vGWTk
...und demnächst mit immer mehr KI-Unterstützung
Mit diesen KI-Features unterstützt euch Google Pixel im Alltag
https://blog.google/intl/de-de/produkte/hardware/ki-features-pixel-7-alltag/
Gruselig!!
Ob es besonders schlau oder dumm, gut oder böse, erlaubt oder nicht erlaubt war alle öffentlich im Internet verfügbaren Daten zu scrapen (einsammeln und speichern) und dann zu verarbeiten ist bislang ungeklärt. IMHO ist das Scrapen sicherlich erlaubt, während jedoch (1) die Zulässigkeit zur Verarbeitung all dieser Daten, ohne Einwilligung von Hunderttausenden, schon recht fragwürdig erscheint. Spätestens aber (2) die Verbreitung eines so erzeugten Modells und schliesslich dann auch noch (3) die Kommerzialisierung erscheint mir äusserst unrechtmässig.
Allerdings ist jetzt der berühmte "Geist aus der Flasche" frei und kehrt nicht mehr dahin zurück von wo er kam. Das ganze KI-Zeugs ist leider unumkehrbar. Die Verbreitung und anschliessende Singularität der KI ist absehbar. Was uns bleibt ist, damit zu leben, es richtig einzuordnen und den korrekten Umgang zu erlernen. Einerseits ist die Anwendung von KI faszinierend, andererseits möchte man sich lieber nicht vorstellen, was solche KI-Werkzeuge in den Händen von bösen Menschen (Schurken, Diktatoren... ) bzw. im neuartigen Überwachungskapitalismus alles anrichten könn(t)en. Der großflächigen Manipulation sind Tür und Tor geöffnet. Dagegen sind "Fake News" nur Kinderkacke!
Zukünftig wird man bei Bild, Sprache, Musik, Video nicht mehr zwischen mensch-gemacht oder maschinell-erstellt unterscheiden können. Möglicherweise wird es eine Subkultur geben, die zumindest in der Lage ist wirklich Menschlich-Erstelltes zu kennzeichnen. Mein bisheriger Eindruck: Es ist eine Art "Lackmustest", der uns zeigen wird, ob wir als Menschheit wirklich einen freien Willen besitzen, der uns von Maschinen unterscheidet und / oder ob unsere eigene Kreativität die einer Maschine übertreffen kann und tut.
Letztlich müssen wir uns bewusst sein: Alle Informationen und das gesamte Wissen dieser Welt, über das wir heute verfügen, haben wir nur weil es unzählige Generationen vor uns erarbeitet haben. Wir sind deshalb - aber vergessen es ständig - auch nur "Zwerge auf den Schultern von Riesen"!
Zum Thema Totlaufen der KI, haben sich auch schon andere Menschen Gedanken gemacht. Hier ein Artikel dazu: https://www.heise.de/news/Kuenftige-KI-Modelle-potenziell-von-Demenz-bedroht-9209900.html
Einen Einspruch bei dem ansonsten sehr gut geschriebenen Artikel. Man sollte nicht von einer "KI" sprechen. Das Wort ist fake und reine Irreführung. Von Intelligenz zu sprechen macht nur dann einen Sinn wenn es sich um ein Lebewesen handelt. Ein Automat bleibt ein Automat und sein Output wird für den Automaten immer bedeutungslos bleiben.
Ich würde ein Technisches Artefakt das über so was wie Intelligenz verfügt nicht von vorneherein ausschliessen. Aber mit der Einschätzung dessen was man im Moment als "KI" bezeichnet hast du wohl recht.